Study/Data Centric
데이터 수집시 주의사항
김 도경
2025. 3. 6. 16:04
라이선스
- 저작권과 라이선스
- 인간의 지적 활동을 통하여 얻어진 무형적 재산(intangible property)을 ‘지식재산’이라고 하며 제작자에게 저작권, 특허권, 상표권 등의 ‘지식재산권’을 통해 그 권리를 보호함
- 이 중 ‘저작권(copyright)’은 창작물에 대하여 창작자(저작자)가 창작과 동시에 취득하는 권리를 뜻함
- 저작권법은 저작물의 그 목적, 형태 등에 관계없이 모두 동일한 수준의 독점적 권리를 제공함 … “All right reserved”
- 이러한 점을 보완하여, 법적인 해석이 모호해지거나 의도된 바와 다르게 사용되지 않도록 ‘라이선스(license, 이용허락)’를 통해 다른 사람이 저작물을 이용할 수 있는 권한을 부여함
- 물론 사용자는 저작자가 라이선스를 통해 정한 제약조건을 따라야 함
- 저작자 또한 자신이 의도하는 바를 확실히 하여 라이선스를 결정해야 함 - Data-Centric AI에서 고려해야 할 라이선스 두 가지
- 코드 → 오픈 소스 라이선스 (OSL) 일반적인 콘텐츠에 사용되는 CCL은 부적합 단, 일부 CCL은 사용 가능
- CC BY-SA : GPLv3 단방향 호환
- CC0 Public Domain : 소프트웨어에도 사용 가능
- 데이터 → 크리에이티브 커먼즈 라이선스 (CCL)
- 일반적인 콘텐츠에 사용되는 CCL을 사용함 - 저작권과 CCL
- 저작권 (Copyright) : 시, 소설, 음악, 미술, 영화, 연극, 컴퓨터프로그램 등과 같은 ‘저작물’에 대하여 창작자가 가지는 여러 가지 권리의 전체
- 크리에이티브 커먼즈 라이선스 (Creative Commons License, CCL; 자유이용허락표시) : 비영리기구인 크리에이티브 커먼즈에서 만든 저작물 관련 라이선스
- 침해 사례 - 복제, 배포가 불가능한 창작물을 무단으로 도용하여 모델 학습에 사용
- 이용허락조건 : CCL은 아래의 네 가지 라이선스 요소들을 조합하여 만들어짐
1. 저작자 표시 (Attribution, BY) → 데이터 배포 시 저작자 표시 필요
- 저작자의 이름, 출처 등 저작자를 반드시 표시해야 한다는 필수 조건
- 저작물을 복사하거나 다른 곳에 게시할때도 반드시 저작자와 출처를 표시해야 함
2. 비영리 (Noncommercial, NC) → 연구 등의 비영리적 목적으로만 사용 가능
- 저작물을 영리 목적으로 이용할 수 없으며, 영리목적의 이용을 위해서는 별도의 계약이 필요함
3. 변경금지 (No Derivative Works, ND) → 원시데이터로 사용 불가
- 저작물을 변경하거나 저작물을 이용해 2차 저작물을 만드는 것을 금지
4. 동일조건변경허락(Share Alike, SA) → 동일한 조건으로 데이터를 배포해야 함
- 2차 저작물 창작을 허용하되, 원 저작물과 동일한 라이선스를 적용해야 함 - 오픈 소스 라이선스란
- 소프트웨어 라이선스 (Software License) : 소프트웨어를 사용, 복제 및 배포할 수 있는 권한과 조건을 규정한 계약 또는 법적인 문서
- 상용 소프트웨어의 경우, 사용자에게 라이선스를 부여하고 사용자는 그 대가를 어떻게 지ༀ할 것인지의 내용으로 구성됨
- 오픈 소스 소프트웨어 (Open Source Software, OSS; 공개SW) : 소스코드가 공개되어 있는 소프트웨어를 말하며, 일반적으로 자유롭게 복제/배포/수정할 수 있음
예) Linux 커널, 아파치 웹서버, Firefox 웹브라우저, MySQL
- 오픈 소스 라이선스 (Open Source License, OSL) : 오픈 소스 소프트웨어를 무료로 사용, 수정, 복제 및 배포할 수 있도록 하는 소프트웨어 라이선스 - 침해 사례 - Artifex vs. Hancom
- 한컴은 아티팩스가 개발한 오픈 소스 렌더러인 ‘Ghostscript’를 사용하였으나, 라이선스 조건을 준수하지 않음
- 아티팩스는 듀얼 라이선스를 Ghostscript에 적용하였는데, 이는 무료로 사용하되 수정된 소스 코드를 공개하거나 사용료를 내고 구매해야 하는 규정에 속했음
- 한컴은 Ghostscript를 사용한 PDF 변환기를 이용하였으나 소스 코드를 공개하거나 이용료를 지불하지 않음
- 아티팩스는 한컴을 소송하였고(2016.12), 한컴은 205만 달러(약 23억 원)의 합의을 지불하고 합의함
- 한컴은 아티팩스에서 요청한 2016년 8월 즉시 해당 코드를 소프트웨어에서 삭제하였으나 그간 사용한 로열티에 상응하는 대가를 지불해야 했음 - BSD형 라이선스
- 비교적 오랜 역사를 가진 라이선스들로, 소스코드 제공 의무가 없으며 그 외의 의무사항도 비교적 간단함 라이선스를 만든 기관의 이름을 따 명명함
- BSD(Berkeley Software Distribution) License : 재배포에 대한 제약이 거의 없는 자유로운 라이선스
- Apache License : 특허 문제에 대한 명시적인 규정이 있으며, 아파치 재단에서 만든 소프트웨어들이 이를 사용함
- MIT License : BSD에서 파생된 라이선스로, 문구가 짧으며 상업적 사용에 대한 출처 표시도 의무가 아님 - GPL형 라이선스
- 대부분 FSF(Free Software Foundation)에서 주도하여 만든 것으로, 카피레프트 조항과 소스코드 제공 의무를 가지고 있다는 점이 BSD형 라이선스와의 큰 차이점 카피레프트의 적용 범위 및 소스코드 제공 의무에 따라 아래의 세 가지로 나뉨
- GPL : 사용한 소프트웨어를 무조건 동일 라이선스 즉, GPL로 공개해야 함
- AGPL : 소프트웨어를 배포하지 않고 네트워크 서버에 의해 서비스를 제공하는 경우에도 소스코드 제공 의무가 적용됨
- LGPL : 라이브러리가 GPL을 사용할 경우 이를 활용한 모든 소프트웨어가 GPL로 배포되어야 한다는 문제를 해결하기 위해 해당 라이브러리를 이용한 응용프로그램은 소스 코드 공개 의무를 갖지 않도록 만듦 - MPL형 라이선스
- 주로 기업들이 주도하는 오픈소스 프로젝트에서 사용하는 라이선스 처음부터 법률가들이 참여하여 만들었기 때문에 정교한 대신 복잡하고 이해하기 어려움
- MPL : GPL과 유사하나 보다 상세하게(파일 단위로) 라이선스의 적용 범위를 결정함
ex) MPL 코드가 사용되지 않은 코드 파일은 MPL 라이선스로 배포할 의무가 없음
- EPL : 프로그램의 모듈 단위로 라이선스의 기여 정도를 따져서 라이선스의 적용 범위를 결정함
개인정보보호
- 개인정보 1) 살아 있는 2) 개인에 관한 3) 정보로서 4) 개인을 알아볼 수 있는 정보
- 해당 정보만으로는 특정 개인을 알아볼 수 없더라도 5) 다른 정보와 쉽게 결합하여 알아볼 수 있는 정보
1) 사망한 자, 법인, 단체 또는 사물 등에 관한 정보는 개인정보가 아님
2) 여럿이 모여서 이룬 집단의 통계값 등은 개인정보가 아님
3) 정보의 종류, 형태, 성격 등에 관련 없이 모두 개인정보가 될 수 있음
4) 특정 개인을 알아보기 어려운 정보는 개인정보가 아님 : 이 때, ‘알아보기 어려운’의 주체는 해당 정보를 처리하는 모든 사람에 해당함
5) 결합 대상이 될 다른 정보의 입수 가능성과 결합 가능성이 높아야 함
예) 차량번호 : 자동차등록원부 등 다른 정보와 쉽게 결합하여 개인을 알아볼 수 있음
- 만일 결합하는 데에 상당한 시간, 비용 등이 든다면 이는 개인정보에 해당하지 않음 - 개인정보의 종류
- 개인의 정보는 다양한 법령에 의해, 다양한 방식으로 보호받고 있음
- 고유식별정보 : 개인을 고유하게 구별하기 위해 식별된 정보로, 일반개인정보와 구분⋅관리해야 함 (개인정보 보호법 제24조)
○ 주민등록번호, 여권번호, 운전면허번호, 외국인등록번호
- 민감정보 : 사상⋅신념, 노동조합⋅정당가입⋅탈퇴, 정치적 견해, 건강정보, 성생활 등에 관한 정보 (개인정보 보호법 제23조)
○ 건강정보 : 개인의 건강, 병력 등에 관한 정보
○ 생체정보 : 개인의 신체적, 생리적, 행동적 특징에 관한 정보 (개인정보 보호법 시행령 제18조)
○ 결제정보 : 입금내역, 결제기록 등의 금융 정보 (신용정보법, 전자상거래법 등)
- 개인위치정보 : 개인의 위치에 관한 정보 (위치정보법)
- 개인영상정보 : 영상정보 중 개인의 초상, 행동 등 개인을 식별할 수 있는 정보 (개인정보 보호법 제2조) - 개인정보 침해 사례
- 기존에 업체가 서비스했던 연애⋅심리 관련 앱(A)을 통해 수집한 실제 카카오톡 대화 내역을 데이터로 활용하여 챗봇(B)을 제작 → 개인정보를 챗봇에게 물어보면 대답해주는 문제가 발생 → 1억 원 상당의 과징금·과태료 행정 처분 - AI 관련 개인정보보호 6대 원칙@ 개인정보위원회
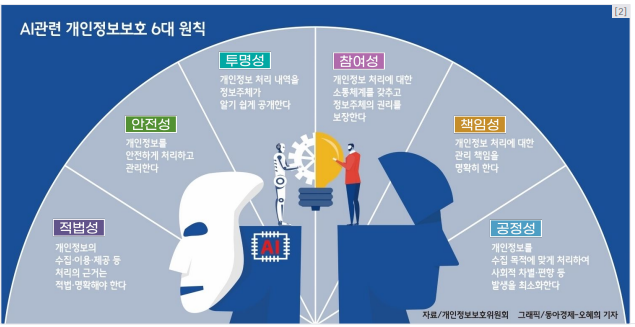
- 개인정보 비식별화 (De-Identification)
- 개인정보 내에서 개인을 식별할 수 있는 요소를 제거하여 특정 개인을 알아볼 수 없게 하는 조치 - 도메인별 비식별화 방법
- 수치형 데이터 : 데이터 범주화, 라운딩 등
- 이미지·동영상 데이터 : 모자이크·블러 처리, 크롭(자르기) 등
- 텍스트 데이터 : 이름, 민감정보 키워드 데이터 변환 등
- 음성 데이터 : 크롭(자르기) 등
윤리
- 인공지능의 사회적 영향력
- 인공지능의 ༀ격한 발전은 사회 전반에 긍정적으로도, 부정적으로도 지대한 영향을 미치고 있음 - 인공지능의 윤리적 이슈들
→ 향후 어떤 AI⋅로봇 관련 윤리적 이슈가 부상할지 예측하기 위해 빅데이터 분석과 미래연구 기법을 활용해 도출한 이슈들
- 2017년 연구임에도 여전히 해결되지 않은 문제들 산재
- 나아가 실제 인공지능 기반 서비스들이 배포되면서 ‘알고리즘 차별’, ‘선정성’ 등의 이슈도 함께 대두됨
- 대체로 의도하지 않았으나 발생한 문제들 - 인공지능 윤리 기준
- 이러한 이슈를 미연에 방지하기 위해, 과학기술정보통신부와 정보통신정책연구원에서는‘인공지능(AI) 윤리기준’을 발표 (20.12.23)
- 인공지능 윤리의 기준들 또한 데이터와 밀접한 관계를 맺고 있음 - 데이터 윤리의 필요성
- MIT Moral Machine : 인간은 자신의 문화권에서 습득한 경험과 지식에 영향을 받음
- Speech2Face : 마찬가지로, 인공지능은 학습에 사용된 데이터에 영향을 받음 - 데이터 편향성 : 데이터의 분포가 어느 한 쪽으로 치우쳐진 상태 혹은 그러한 정도
- 데이터가 편향되어 있을 경우, 이를 학습에 사용한 딥러닝 모델 또한 의도치 않게 편향된 결과를 도출할 수 있음 ( ∵ 딥러닝 모델 학습의 근간은 베이지안 추론이므로 )
- 이를 그대로 서비스에 적용할 경우, 불공정한 차별을 발생시킬 수 있음 - 데이터 편향성 사례
- 인종 차별 사례 - 피부색에 따른 얼굴인식시스템의 인식률 차이 발생
- 성별 차별 사례 - 이미지 검색 결과
- 지역 차별 사례 - 범죄 발생 가능 지역 예측 - 데이터의 편향성을 줄이는 방법
- 데이터 다양성 확보 및 균형 조정 : 다양한 소스에서 데이터 수집, 불균형한 데이터 라벨에 대해서는 분포를 조정
- 편향을 감지 및 수정해주는 모델 사용 : 모델이나 데이터의 편향을 감지하고 수정해주는 robust한 알고리즘 및 모델을 활용
- 투명성과 책임성을 강조하여 서비스 운영 : 인공지능 시스템의 작동 원리와 의사 결정 과정을 투명하게 설명하고 책임을 지는 방안 - 사회적으로 문제가 될 수 있는 요소들
- 아래와 같은 유해한 요소들을 탐지하는 문제를 ‘Toxicity Detection’ 혹은 ‘Explicit Content Detection’이라고 함
- 특히 텍스트 데이터일 경우는 ‘Hate Speech Detection’이라고 하며, 선정적 요소를 찾는 문제에는 노출의 정도를 찾는 ‘Nudity Detection’ 등이 있음