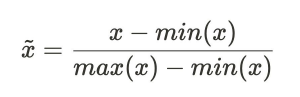[2024.11.05] 필수 온라인 강의 Part16 Machine Learning Advanced CH03 파생변수만들기
파생 변수 만들기
파생 변수 - 기존 변수의 정보를 토대로 정제 및 생성된 새로운 변수 - 함수 변환, 스케일링, 구간화를 기반으로 기존 변수를 새롭게 정제하는 방식 - 변수들의 수치 범위를 동일하게 변환, 정규분포를 따르도록 변환 - 모델의 입력 포맷에 맞게 변환하여 성능 상승 효과 - 변수들 간의 상호작용 합성, 집계를 통해 새로운 변수를 도출하는 방식 - 기존 변수가 가진 정보력을 조합하여 새로운 의미(인사이트)를 가진 변수를 도출 - 단순 합성이 아닌, 해결하려는 문제에 대한 도메인 지식과 연관 - 파생 변수가 중요한 이유 - 성능적인 관점 - 알고리즘 입장에서 변수 간 연관 관계를 파악하기 수월하기 때문에 과적합을 방지할 수 있는 효과 - 해석적인 관점 - 도메인 기반의 파생 변수는 인간 친화적인 분석 관점을 제공 - 메모리 관점 - 파생 변수는 정보의 손실을 최소화하면서 압축 효과에 따른 신속한 전처리
변수 자체를 변환하는 방식
함수 변환 - 수치형 변수의 로그 변환 (Log Transform) - 비대칭(Right-Skewed) 된 임의의 분포를 정규분포에 가깝게 전환 - 데이터의 정규성은 모델(회귀)의 성능을 향상 - 데이터의 스케일을 작고, 균일하게 만들어 데이터 간의 편차를 줄이는 효과
- 아래처럼 np.log를 이용하면 로그 변환이 가능하지만, 관측치에 0이 포함된 경우 경고 발생 -> np.loglp = log(x+1)을 사용함
- 제곱근 변환 (Square Root Transform) - 변수에 제곱근을 적용하여 전환 - 제곱근 변환의 효과는 앞선 로그 변환과 유사 (정규성, 선형 관계 생성, 데이터 스케일 축소, 이상치 제거)
- 로그 & 제곱근 변환 비교logx / 제곱근x / sqrt 값 - 두 변환 모두 왜도(Skewness)를 줄여 정규분포에 가깝게 변환 - 로그 변환은 큰 관측 값의 영향을 줄이기 때문에 분포가 오른쪽으로 치우치는 경향 - 제곱근 변환은 비교적 큰 관측 값에 영향을 덜 주기 때문에 로그 변환 분포에 비하여 완화되는 경향
- Box-Cox 변환
- 로그 변환, 제곱근 변환, 거듭제곱 변환을 통합한 방법 (scipy 패키지의 boxcox1p를 적용) - 람다 파라미터를 변화 시키면서 차이를 확인 - 람다(λ) 파라미터 값을 토대로 로그, 제곱근, 거듭제곱 변환을 적절하게 혼합하여 사용하는 방법
스케일링 (Scaling) - Min-Max 스케일링
- 연속형 변수의 수치 범위를 0-1 사이로 전환 - 각기 다른 연속형 변수의 수치 범위를 통일할 때 사용 - 큰 스케일을 가지고 있는 Salary 변수를 정규화 - 데이터의 스케일이 0-1 값으로 변화된 것을 확인 - 함수 변환과 다르게 데이터의 분포는 변하지 않는 것이 특징
- 표준화 (Standardization)
- 변수의 수치 범위(스케일)를 평균이 0, 표준편차가 1이 되도록 변경(Z-score) - 평균과의 거리를 표준편차로 나누기 (정규분포의 표준화 과정) - 평균에 가까워질수록 0으로, 평균에서 멀어질수록 큰 값으로 변환 - 큰 스케일을 가지고 있는 Salary 변수를 표준화 - 평균을 0, 표준편차는 1으로 변경 - 표준화 후 데이터의 스케일이 -3~3 값으로 변화
기타 변수 - 분할 (Split) - 이름(Name)과 같은 짧은 단위의 문자를 분할하여 통일성 있는 데이터를 구성 - 그룹화를 통해 잠재적인 정보를 추출 - 아래 예제처럼, 성과 이름을 분리하여 성(First name) 별로 그룹화를 시키는 것이 가능
- 시간 변수 - 날짜 및 시간 변수는 시점이라는 풍부한 정보를 담고 있기 때문에 모델에 효과적으로 활용 - 학습 모델이 인식할 수 있도록 숫자 데이터로 변환하는 것이 필요 - 시간 요소를 분리 추출하거나, 시간 차(Time delta)를 파생 변수로 변환 - 날짜 및 시간 데이터를 연도, 월, 일과 같은 연속적인 수치 형태로 추출하는 과정 - 이외에도 주차(Day of week), 일년 기준 지난 일수(Day of year) 형태로 파생 - 구간화를 응용하여 시간의 범주화도 가능
- 시간 차(Time Delta) - 특정 시점을 기준으로 해당 시점과의 차이를 구성하여 변수로 활용 - 이를 응용하여 연휴, 명절, 주말과 같은 의미 있는 시점을 기준으로 파생 변수를 생성 가능
변수 간의 관계를 활용하는 방식 - 변수 결합 - 서로 다른 의미를 담고 있는 변수를 통해 새로운 의미를 파생하기 때문에, 알고리즘 모델의 데이터 해석 용이 - 도메인 지식과 연관하여 변수 도출의 객관성을 유지 하는 것이 중요 - 예시 ) 통신사 월 이용 금액 -> 멤버쉽 등급을 파생 / 1층+2층 면적 -> 전체 면적
- 통계 기반 변수 - 데이터 집계 후 평균, 중앙, 최대, 최소 등의 통계치를 파생 변수로 적용 - 해당 관측치가 전체에서 차지하는 상대적인 위치를 쉽게 표현 가능 - 예시 ) 카테고리 별 대푯값인 평균값과 상품의 개별 가격을 결합 -> 상품의 가격대(비싼 정도)를 파생
사례를 통해서 배우는 파생변수 만들기(실습)
1. 주가(OHLCV) 데이터셋 실습 해보기 - Yahoo Finance ( 주식, 환율과 같은 금융 정보를 제공하는 플랫폼 ) OHLCV (Open High Close Low Volume) 데이터셋
실습 데이터 재구성하기 - OHLCV 데이터셋의 크기가 방대하고, 학습 모델에 적절치 않기 때문에 데이터셋을 재구성 필요.
# 데이터셋 파일 위치로 경로 수정
os.chdir('데이터셋 파일이 있는 폴더 경로')
# OHLCV 데이터셋 불러오기
OHLCV_file = "OHLCV.parquet"
OHLCV_data = pd.read_parquet(OHLCV_file)
-OHLCV 데이터셋의 날짜 범위를 2020년 1월에서 2023년 7월 사이로 축소
# 날짜는 데이터셋의 index로 되어 있습니다.
# .loc을 통해서 날짜 범위를 지정해줍시다.
OHLCV_data = OHLCV_data.loc["2020-01-01":"2023-07-31"]
# 상장법인정보 파일도 불러오도록 하겠습니다.
company_file = "Company.parquet"
company_data = pd.read_parquet(company_file)
# OHLCV 데이터셋
display(OHLCV_data.head(10))
# 현재 데이터프레임의 인덱스가 날짜로 되어있음
# 분석 편의를 위해서 Date컬럼을 새로 만들고, 인덱스는 새로 초기화
OHLCV_data["Date"] = OHLCV_data.index
OHLCV_data.reset_index(drop=True, inplace=True)
display(OHLCV_data)
- 상장과 OHCLV랑 함께 보기
# 상장법인정보 데이터셋
display(company_data.head(10))
# 두 파일을 결합시켜 OHCLV와 상장법인정보를 함께 볼 수 있게 결합
OHLCV_data = pd.merge(OHLCV_data, company_data, on="code", how="inner")
display(OHLCV_data)
- 불필요한 컬럼 삭제, 실습을 위해서는 정답(레이블) 컬럼을 구성 : 다음날 종가(Close)를 정답 컬럼
# 컬럼이 너무 많아 데이터프레임 출력이 불편하니, 불필요한 컬럼을 제외하는 함수
except_cols = ["industry", "products", "listing_date", "closing_month", "region"]
def get_display_cols(except_cols):
return [col for col in OHLCV_data.columns if col not in except_cols]
display_cols = get_display_cols(except_cols)
# 이번 강의에서는 파생 변수를 제작하는 것 외에도,
# 다음날 종가(Close)를 예측하기 위한 정답(Target)값도 제작
# 종목(code)로 집계 후 다음날 종가(Close)를 Target 변수에 삽입
OHLCV_data["Target"] = OHLCV_data.groupby("code")["Close"].shift(-1)
display(OHLCV_data[display_cols])
시계열 데이터란? - 시계열 데이터는 일정 시간이나 특정 순서에 따라서 기록된 데이터 구조 - 시간에 따른 기상, 실시간 센서 데이터 등과 같이 시간에 종속되어 있는 형태를 시계열 데이터
# 날짜 범위 생성 (예: 2020년 1월 1일부터 1년간)
dates = pd.date_range(start="2020-01-01", periods=365, freq="D")
values = np.random.randint(0, 45, size=len(dates))
# 시계열 난수 데이터 생성 (날짜를 인덱스로 설정)
time_series = pd.Series(values, index=dates)
# 생성된 시계열 데이터 출력
display(time_series)
# 시계열 데이터 시각화
plt.figure(figsize=(15, 6))
sns.lineplot(time_series)
plt.xlabel("Time")
plt.ylabel("Temperature(°C)")
plt.title("Time Series Data")
plt.grid(True)
plt.show()
# 일일 수익률은 두가지 방법으로 계산
# 첫번째는 수식을 직접 명시하는 방법
display(
((OHLCV_data["Close"] / OHLCV_data["Close"].shift(1)) - 1) * 100
)
# 두번째 방법은 pct_chage 기능을 이용
# pct_chage는 행과 행사이의 차이를 구하는 기능
# 두 방법 모두 결과는 동일
OHLCV_data["DailyReturn"] = OHLCV_data["Close"].pct_change() * 100
display_cols = get_display_cols(except_cols)
display(OHLCV_data[display_cols])
# 이동 평균은 rolling 기능을 이용하여 계산
# rolling은 윈도우(기간)을 설정하여 특정 연산
# window는 몇일 간의 이동 평균을 구할지 설정하는 파라미터
display("예) 20일간의 종가 합산")
display(OHLCV_data["Close"].rolling(window=20).sum())
# 과거의 종가를 이용해서 이동평균을 구하기 때문에 첫 부분에는 결측치를 만듬
display_cols = get_display_cols(except_cols)
display(OHLCV_data[display_cols].head(30))
- 삼성전자 종목을 기준으로 이동평균선 그려봄
# 결측치 들이 많이 생겼기 때문에 결측치들을 모두 제거
samsung_data = OHLCV_data[OHLCV_data["code"] == "005930"].copy()
samsung_data = samsung_data[
samsung_data["MovingAverage5d"].notnull() &
samsung_data["MovingAverage20d"].notnull() &
samsung_data["MovingAverage60d"].notnull() &
samsung_data["MovingAverage120d"].notnull()
]
# 오늘이 2023-03-01이라고 가정
# 2023-01-01 ~ 2023-03-01까지의 데이터 확인
samsung_data = samsung_data[(samsung_data["Date"] >= "2023-03-01") & (samsung_data["Date"] <= "2023-03-31")]
# 날짜 형식을 숫자로 변환해야 시각화를 하기 수월함
samsung_data["Date"] = samsung_data["Date"].map(mpdates.date2num)
# 차트를 그리기 위해서 필요한 데이터만 뽑아봄
samsung_data = samsung_data[
[
"Date",
"Open",
"High",
"Low",
"Close",
"MovingAverage5d",
"MovingAverage20d",
"MovingAverage60d",
"MovingAverage120d",
]
]
fig, ax = plt.subplots(figsize=(10, 5))
# 아래 함수를 이용해 캔들차트
candlestick_ohlc(ax, samsung_data.values, width=0.6, colorup="g", colordown="r")
# X 축에 주간 구분선을 추가
ax.xaxis.set_major_locator(mpdates.WeekdayLocator(mpdates.MONDAY))
ax.xaxis.set_minor_locator(mpdates.DayLocator())
# 아까 숫자로 변환한 날짜 데이터를 보기 좋게 형식 변환
ax.xaxis.set_major_formatter(mpdates.DateFormatter("%Y-%m-%d"))
# 반복문을 통해 이동평균선
for col in [
"MovingAverage5d",
"MovingAverage20d",
"MovingAverage60d",
"MovingAverage120d",
]:
ax.plot(samsung_data["Date"], samsung_data[col], label=col, linestyle="--")
# 필요한 범례들을 작성
plt.title("Samsung Electronics Co., Ltd.")
plt.xlabel("Date")
plt.ylabel("Price")
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.show()
- 볼린저 밴드 (Bollinger bands) - 이동평균을 기준으로 상한(Upper), 하한(Lower) 밴드를 구성하여 추세와 변동성을 파악하는 기술
# 표준편차에 대한 상한 및 하한 밴드의 배수 설정
std_multiplier = 2
std = OHLCV_data.groupby("code")["Close"].transform(lambda x: x.rolling(window=20).std())
# 상한은 일반적으로 20일 이동평균에 2배의 표준편차 더하기
# 하한은 일반적으로 20일 이동평균에 2배의 표준편차 빼기
OHLCV_data["UpperBollingerBand"] = OHLCV_data["MovingAverage20d"] + (std_multiplier * std)
OHLCV_data["LowerBollingerBand"] = OHLCV_data["MovingAverage20d"] - (std_multiplier * std)
- 이동평균선에 볼린저 밴드를 추가하여 시각화
# 결측치 들이 많이 생겼기 때문에 결측치들을 모두 제거해주겠습니다.
samsung_data = OHLCV_data[OHLCV_data["code"] == "005930"].copy()
samsung_data = samsung_data[
samsung_data["MovingAverage5d"].notnull() &
samsung_data["MovingAverage20d"].notnull() &
samsung_data["MovingAverage60d"].notnull() &
samsung_data["LowerBollingerBand"].notnull() &
samsung_data["UpperBollingerBand"].notnull()
]
# 오늘이 2023-03-01이라고 가정
# 2023-01-01 ~ 2023-03-01까지의 데이터
samsung_data = samsung_data[(samsung_data["Date"] >= "2023-03-01") & (samsung_data["Date"] <= "2023-03-31")]
# 날짜 형식을 숫자로 변환해야 시각화를 하기 수월
samsung_data["Date"] = samsung_data["Date"].map(mpdates.date2num)
# 차트를 그리기 위해서 필요한 데이터만 뽑아 보아요.
samsung_data = samsung_data[
[
"Date",
"Open",
"High",
"Low",
"Close",
"MovingAverage5d",
"MovingAverage20d",
"MovingAverage60d",
"MovingAverage120d",
"LowerBollingerBand",
"UpperBollingerBand",
]
]
fig, ax = plt.subplots(figsize=(10, 5))
# 아래 함수를 이용해 캔들차트
candlestick_ohlc(ax, samsung_data.values, width=0.6, colorup="g", colordown="r")
# X 축에 주간 구분선을 추가
ax.xaxis.set_major_locator(mpdates.WeekdayLocator(mpdates.MONDAY))
ax.xaxis.set_minor_locator(mpdates.DayLocator())
# 아까 숫자로 변환한 날짜 데이터를 보기 좋게 형식 변환
ax.xaxis.set_major_formatter(mpdates.DateFormatter("%Y-%m-%d"))
# 반복문을 통해 이동평균선을 그려줍니다.
for col in [
"MovingAverage5d",
"MovingAverage20d",
"MovingAverage60d",
"MovingAverage120d",
]:
ax.plot(samsung_data["Date"], samsung_data[col], label=col, linestyle="--")
for col in [
"LowerBollingerBand",
"UpperBollingerBand",
]:
ax.plot(samsung_data["Date"], samsung_data[col], label=col, alpha=0.3)
# 볼린저 밴드를 위해 투명도를 가진 색을 채워넣기
plt.fill_between(
samsung_data["Date"],
samsung_data["LowerBollingerBand"],
samsung_data["UpperBollingerBand"],
color="red",
alpha=0.05,
)
# 필요한 범례들을 작성
plt.title("Samsung Electronics Co., Ltd.")
plt.xlabel("Date")
plt.ylabel("Price")
plt.xticks(rotation=45)
plt.legend()
plt.show()
- MACD (Moving Average Convergence & Divergence) - 이동평균에서 파생된 기술 - 지수 이동평균(Exponential Moving Average, EMA)은 시계열 데이터에서 최근 관측치에 높은 가중치를 주고, 과거 관측치에는 낮은 가중치를 주어 이동평균을 차등 계산하는 방식
# .ewm를 이용하면 데이터프레임에서 지수가중함수를 손쉽게 제어
# 12일, 26일 각각의 지수가중함수
OHLCV_data['ShortEMA'] = OHLCV_data["Close"].ewm(span=12, adjust=False).mean()
OHLCV_data['LongEMA'] = OHLCV_data["Close"].ewm(span=26, adjust=False).mean()
# 지수가중함수의 차를 구해 MACD를 완성
OHLCV_data['MACD'] = OHLCV_data['ShortEMA'] - OHLCV_data['LongEMA']
# 도메인 지식에 기반한 여러 파생 변수를 제작
display_cols = get_display_cols(except_cols)
display(OHLCV_data[display_cols].head(10))
display(display_cols)
파생 변수 만들기II (상장법인정보 기반) - 업종(industry), 주요 제품(Products), 상장일(listing_date), 결산월(closing_month), 지역(region)이 존재 - "통계 기반 파생 변수"와 "시간관련 파생 변수"는 도메인 지식과 관련된 변수라기 보다는 기존의 변수를 분할하거나 계산하여 제작
# 상장법인정보를 기반해 파생 변수 제작
# 아까 제작한 도메인 지식 기반 파생 변수는 출력 X
except_cols = [
"DailyReturn", "MovingAverage5d", "MovingAverage20d",
"MovingAverage60d", "MovingAverage120d", "LowerBollingerBand",
"UpperBollingerBand", "ShortEMA", "LongEMA", "MACD", "code",
"PriceRange", "AveragePrice", "PriceDirection", "products"
]
display_cols = get_display_cols(except_cols)
OHLCV_data[display_cols].head(10)
# Date, listing_date컬럼은 "2020-01-01" 형태
# 이걸 컴퓨터가 인식할 수 있도록 년,월,일 정수 컬럼으로 나눠서 표현
# Date컬럼 나누기
OHLCV_data["DateYear"] = OHLCV_data["Date"].dt.year
OHLCV_data["DateMonth"] = OHLCV_data["Date"].dt.month
OHLCV_data["DateDay"] = OHLCV_data["Date"].dt.day
# listing_date컬럼 나누기
OHLCV_data["ListingDateYear"] = OHLCV_data["listing_date"].dt.year
OHLCV_data["ListingDateMonth"] = OHLCV_data["listing_date"].dt.month
OHLCV_data["ListingDateDay"] = OHLCV_data["listing_date"].dt.day
# closing_month컬럼은 "12월" 형태이기 때문에 "월"을 빼고 정수만 남김
OHLCV_data["ClosingMonthInt"] = OHLCV_data["closing_month"].str.replace('월', '').astype(int)
# 시간관련 파생 변수를 출력
display(OHLCV_data[
["Date", "listing_date", "closing_month",
"DateYear", "DateMonth", "DateDay",
"ListingDateYear", "ListingDateMonth",
"ListingDateDay", "ClosingMonthInt"
]
])
데이터 인코딩 및 결측치 정리
# sklearn에서 제공하는 LabelEncoder를 활용
label_encoder = LabelEncoder()
OHLCV_data["LEncodedIndustry"] = label_encoder.fit_transform(OHLCV_data["industry"])
OHLCV_data["LEncodedProducts"] = label_encoder.fit_transform(OHLCV_data["products"])
OHLCV_data["LEncodedRegion"] = label_encoder.fit_transform(OHLCV_data["region"])
# Label Encoding 결과를 출력
OHLCV_data[["industry", "products", "region", "LEncodedIndustry", "LEncodedProducts", "LEncodedRegion"]]
frequency_encoder = OHLCV_data["industry"].value_counts()
OHLCV_data['FEncodedIndustry'] = OHLCV_data['industry'].map(frequency_encoder)
# Frequency Encoding 결과를 출력
OHLCV_data[["industry", "FEncodedIndustry"]]
- Target Encoding은 특정(타겟) 변수를 평균으로 인코딩하는 방식
# 각 업종별 종가의 평균 계산
target_encoder = OHLCV_data.groupby("industry")["Close"].mean()
OHLCV_data["TEncodedIndustry"] = OHLCV_data['industry'].map(target_encoder)
# Target Encoding 결과를 출력
OHLCV_data[["industry", "Close", "TEncodedIndustry"]]
# 결측치 모두 제거
OHLCV_data.dropna(inplace=True)
# OHLCV의 0이 되는 이상치 및 결측치는 모두 제거
OHLCV_data = OHLCV_data[(OHLCV_data[["Open", "High", "Low", "Close", "Volume", "Change"]] != 0).all(axis=1)]
- USA House Prices은 주택 시장에서 부동산 가격을 예측을 위해 사용되는 유명 데이터셋
# 학습 및 테스트 데이터셋을 로드
train_df = pd.read_csv("housing_train.csv")
test_df = pd.read_csv("housing_test.csv")
display("Train Dataset")
display(train_df)
display("Test Dataset")
display(test_df)
# 컬럼 정보를 확인
display(train_df.info())
- 결측치 및 이상치 다루기
# 전처리에 앞서, 학습데이터와 테스트를 합쳐 전처리를 진행
df = pd.concat([train_df, test_df], axis=0)
# 추후 사용을 위해 필요한 정보는 다른 변수에 저장.
y_train = train_df["SalePrice"]
train_size = len(train_df)
test_size = len(test_df)
# 불필요한 컬럼은 필요 없으니 제거.
df.drop(columns=["Id", "SalePrice"], inplace=True)
# Series 타입 데이터를 데이터프레임으로 전환
missing_cat_df = pd.DataFrame(df.loc[:, missing_cat_cols].isna().sum())
missing_num_df = pd.DataFrame(df.loc[:, missing_num_cols].isna().sum())
# 범주형 변수의 결측치 시각화
# 차트 크기 설정
plt.figure(figsize=(16, 5))
# 막대(Bar) 차트 생성
sns.barplot(data=missing_cat_df, x=missing_cat_df.index, y=missing_cat_df[0])
# 차트 제목
plt.title("Categorical Missing Value")
# X,Y축 레이블 설정
plt.xlabel("Categorical Variable Columns")
plt.ylabel("Missing Value Count")
plt.xticks(rotation=45)
plt.show()
# drop()은 컬럼을 제거하는 기능
df.drop(columns=["PoolQC"], inplace=True)
- 결측치 대체
# 최빈값으로 대체할 컬럼들을 선정
mode_cols = [
"MSZoning", "GarageYrBlt", "GarageCars", "GarageArea",
"Utilities", "Exterior1st", "Exterior2nd",
"MasVnrType", "Electrical", "KitchenQual",
"Functional", "SaleType"
]
# 반복문과 fillna를 이용하면 손쉽게 변환이 가능.
for col in mode_cols:
df[col] = df[col].fillna(df[col].mode()[0])
# 위와 마찬가지로 결측치를 특정값으로 대체할 컬럼들을 선정.
fill_cols = [
"Alley", "BsmtQual", "BsmtCond", "BsmtExposure", "BsmtFinType1",
"BsmtFinType2", "FireplaceQu", "GarageType", "GarageFinish", "GarageQual",
"GarageCond", "Fence", "MiscFeature"
]
for col in fill_cols:
df[col] = df[col].fillna("Nothing")
# 주차장까지의 직선거리를 평균값으로 대체
df["LotFrontage"] = df["LotFrontage"].fillna(df["LotFrontage"].mean())
- 결측치 회귀 대체
# KNN으로 결측치를 채워놓을 변수 리스트입니다.
knn_cols = [
"MasVnrArea", "BsmtFinSF1", "BsmtFinSF2",
"BsmtUnfSF", "TotalBsmtSF", "BsmtFullBath", "BsmtHalfBath"
]
# 반복문으로 각 컬럼마다 학습 후, 예측을 해봅시다.
for col in knn_cols:
# KNN 회귀관련 인스턴스를 불러옵니다.
knn = KNeighborsRegressor(n_neighbors=10)
# 수치형 변수를 선택합니다.
numerical = df.select_dtypes(np.number)
# 결측값이 존재하지 않는 변수들을 선택합니다.
non_na_num_cols = numerical.loc[:, numerical.isna().sum() == 0].columns
# 결측치가 발생한 컬럼을 y, 관측치가 존재하는 컬럼을 X로 구성합니다.
X = numerical.loc[numerical[col].isna() == False, non_na_num_cols]
y = numerical.loc[numerical[col].isna() == False, col]
X_test = numerical.loc[numerical[col].isna() == True, non_na_num_cols]
# knn을 학습 합니다.
knn.fit(X, y)
# 결측치를 예측합니다.
y_pred = knn.predict(X_test)
# 결측치를 예측된 값으로 채워 놓습니다.
df.loc[numerical[col].isna() == True, col] = y_pred
- 이상치 처리
# 차고 제작연도(GarageYrBlt) 기본 통계치 출력
display(df["GarageYrBlt"].describe())
plt.figure(figsize=(6, 4))
sns.boxplot(x=df["GarageYrBlt"])
plt.title(f"GarageYrBlt")
plt.show()
# 2018보다 큰 값을 가지는 행(Row) 출력
display(df[df["GarageYrBlt"] > 2018])
# 이상치 대체 2207 -> 2007
df.loc[df['GarageYrBlt'] == 2207, 'GarageYrBlt'] = 2007
- 파생 변수 만들기 : 부대시설 여부를 파생 변수로 제작
# 관측치가 1이상이면 부대시설이 존재한다고 가정
# lambda를 이용하면 모든 열에 조건문을 적용
df["hasPool"] = df["PoolArea"].apply(lambda x: 1 if x > 0 else 0)
df["has2ndFloor"] = df["2ndFlrSF"].apply(lambda x: 1 if x > 0 else 0)
df["hasGarage"] = df["GarageArea"].apply(lambda x: 1 if x > 0 else 0)
df["hasBsmt"] = df["TotalBsmtSF"].apply(lambda x: 1 if x > 0 else 0)
df["hasFirePlace"] = df["Fireplaces"].apply(lambda x: 1 if x > 0 else 0)
# 새로 만들어진 파생 변수를 확인
df[["hasPool", "has2ndFloor", "hasGarage", "hasBsmt", "hasFirePlace"]]
df["hasWoodDeck"] = df["WoodDeckSF"].apply(lambda x: 1 if x > 0 else 0)
df["hasOpenPorch"] = df["OpenPorchSF"].apply(lambda x: 1 if x > 0 else 0)
df["hasEnclosedPorch"] = df["EnclosedPorch"].apply(lambda x: 1 if x > 0 else 0)
df["has3SsnPorch"] = df["3SsnPorch"].apply(lambda x: 1 if x > 0 else 0)
df["hasScreenPorch"] = df["ScreenPorch"].apply(lambda x: 1 if x > 0 else 0)
df['RemodAfterBuilt'] = df['YearRemodAdd'] - df['YearBuilt']
# 현재시점 - df['YearRemodAdd']
# clip을 사용하면 하향 임계값(lower bound)를 설정해줄 수 있습니다.
df['RemodAfterBuilt'] = df['RemodAfterBuilt'].clip(lower=0)
- 파생 변수 만들기 : 연면적
# 연면적 계산
df["TotalSF"] = df["TotalBsmtSF"] + df["1stFlrSF"] + df["2ndFlrSF"]
# 비슷한 개념으로 총 화장실 개수 계산
df["TotalBathRooms"] = df['FullBath'] + df['HalfBath'] + df['BsmtFullBath'] + df['BsmtHalfBath']
# 수치형 변수를 min-max scaling
for col in df.select_dtypes(np.number).columns:
df[col] = MinMaxScaler().fit_transform(df[[col]])
# 범주형 변수를 label encoding
for col in df.select_dtypes("object").columns:
df[col] = LabelEncoder().fit_transform(df[col])