* 강의를 듣고 필기한 내용일 이후에 따로 정리한 내용입니다.
* https://glowdp.tistory.com/2 에서 이어지는 게시물 입니다
코드 편집기 추천
- (IDE) Visual Studio Code : 무료 코드 편집기 / 다양한 언어 지원, 확장 프로그램을 통한 기능 추가 가능.
- Sublime text : 가볍고 빠른 편집기
2-5. Python 기본 내장함수와 외장함수
len('Python') -> 6이 출력 , 길이
list('Python') -> ['P', 'y', 't', 'h', 'o', 'n']이 출력 , 리스트로 만들기
abs(-1.2) -> 1.2이 출력 , 절대값
round(1.7) -> 2이 출력 , 반올림
bool(1) -> True이 출력 , 참/거짓
sum([1, 2, 3]) -> 6이 출력 , 합계
max([1, 2, 3]) -> 3이 출력 , 최대
min([1, 2, 3]) -> 1이 출력 , 최소
def func(x):
return x**2
func(5) -> 5가 출력- lamda 함수를 사용하는 경우
func = lambda x: x**2
func(5) -> 5가 출력- lamda 함수란 == 익명 함수 (anonymous func)
- : 의 기능
- index number 기준 범위 지정시
- multi -line code block
- dict (key & value)
- lamba function : lamba
2-6. 라이브러리 활용하기
- 코드가 길어지게 되면, 코드를 보기 힘들어짐->유지보수가 힘듬
- 단일.py = module
- 이 module을 모아둔 것이 library = Package
- 모듈 하나 만들기 -> 이런 모듈을 모아서 package(library)를 만듬
%%writefile module_example.py%%로 시작 하는 것 : 파이썬 코드X, 주피터 노트북의 기능.
- Jupyter 노트북에서 셀 내용을 파일로 저장할 때 사용하는 명령어
-> 이후에 작성된 코드를 [module_example.py] 라는 파일로 저장
%%writefile module_example.py
# @ module_example.py
def print_something() :
print('Hello world!')
def sum_nums(num1, num2) :
result = num1 + num2
return result이 내용은 module_example.py을 만들어서 아래의 코드를 넣어라는 의미. 이런 코드를 만든 후,
import module_example
module_example.print_something()
module_example을 불러서, module_example.print_something()를 활용가능 -> 'Hello world!'가 출력됨
- . (마침표 연산자)를 사용하는 경우
- 변수.함수(or변수) <- temp.lower()
- 라이브러리.함수(or변수) <- numpy.array() - 라이브러리를 설치하기
- jupyter notebook 라이브러리 설치 방법은 2가지이다. : 파이썬 라이브러리리가 2개가 있다.
1. cmd에서 불러오기
- pip install 라이브러리_이름 : 파이썬 메인 라이브러리 저장소로부터 가져오기
- conda install 라이브러리_이름 : 아니콘다에서 관리하는 저장소로 가져오기
2. jupyter 노트북에서 불러오기
- !pip install 라이브러리_이름
- !conda install 라이브러리_이름
- 기본적으로 사용은 conda install을 사용 : 아나콘다 쓰는 이유 : 버전호환성을 지켜주기 때문
- 기본적으로 콘다로 하기 : 천천히 꼼꼼히 모든 라이브러리를 체크후, 이번 라이브러리와 버전이 문제 없는지를 확인해줌.
: 각각의 라이브러리 별로 다 알려주고, 확인후에 설치가 가능.
- 단점 : 너무 꼼꼼해서 너무 느리다 - 기본적으로 cmd에서 설치하길 권장. 주피터노트북에서는 문제가 많음
- cmd랑 아나콘다 프롬포트랑의 차이, 거의 없기에 cmd만 사용해도 괜찮음
- 라이브러리 가져와서 사용하기
- import 라이브러리이름을 통해서 불러올 수 있음
- import 라이브러리이름 as 별명 :
방법 1. numpy 함수 불러오기
import numpy
방법 2. numpy 함수에 별명 붙여서 가져오기 : 가장 통상적으로 쓰는 방법
import numpy as np
- 별명이 어느정도 약속이 되어있음
- numpy (수치형 자료계산 및 연산 ) : np : import numpy as np
- pandas (정형 데이터 전처리 및 분석) : pd : import pandas as pd
- matplotlib (데이터 차트 시각화) : plt : import matplotlib.pyplot as plt
- seaborn (보다 개선된 데이터 시각화) : sns : import seaborn as sns
- beautifulsoup4(bs4) (웹 데이터 추출(web scraping)) from bs4 import
- nltk (자연어 데이터 전처리) : import nltk
- scikit-learn (전통적인 머신러닝 알고리즘) : from sklearn import
방법 3. 라이브러리에 여러함수를 특정햇거 불러오기 -> 추천하지 않음 : 어떤 라이브러리인지 헷갈릴 가능성이 큼.
- 함수 이름이 절대 겹치지 않을 때는 사용할 만하다. 이름이 긴 애들은 이렇게도 가져옴
from numpy import array, ndarray
random 라이브러리
import random
x = random.random()
x -> 랜덤한 숫자가 나옴- 랜덤한 정수를 얻고 싶을 때, 사용하기
x = random.randint(1, 100) # 1과 100 사이의 '정수'
xTab을 사용해서 randint를 바로 찾아 불러올 수 있음
Shift + Tab 사용하여 무엇이 빠졌는지에 대해서 찾을 수 있음
os 라이브러리
import os
os.getcwd() # get current working directory -> 주피터노트북의 현재 위치 출력- os 함수 : 외장함수
- 운영체제와 관련된 라이브러리, 파일 이동, 파일 삭제, 윈도우작업을 코드로 할 수 있게 해주는 라이브러리,
- 특정한 폴더를 지정하면 이름을 다 보여주고, 파일에 있어서 수정을 가능하게 해줌
(예시) 이름들을 폴더에 이미지가 3000개가 있다면, 일괄적으로 파일 이름을 바꾸기, 100개단위로 묶기 - getcwd = get current working directory : 현재 작업폴더
- 주피터노트북의 위치가 어디인지 알아야하기에, 이걸 확인하고 싶을 때 쓰는 코드. - pip 명령어 살펴보기 : pip + [ list/freeze/check, show/install/uninstall library_name, search search_keyword ]
라이브러리 목록을 불러오기
pip freeze
pip freeze > requirements.txt # -> pip install -r requirements.txt- requirement를 사용하면 파일로 받을 수 있음
라이브러리가 말썽을 일으켜서 지우고 다시 설치를 하고 싶을 때 사용
pip show numpy
pip uninstall numpy (주의) 라이브러리를 지우고
pip install numpy==1.19.5 (주의) 라이브러리를 다시 설치하기1. show를 통해서 라이브러리의 버전을 확인하고
2. 라이브러리를 지우고
3. 라이브러리를 재설치하기 -> 이전 버전과 동일하거나 업그레이드를 해서 하기
특정 라이브러리를 설치하기 위한 설치파일을 다운로드 받기 위함
pip download django- 확장자는 주로 .whl (wheel)의 줄임말, 이런 파일을 다운로드 하게 해줌
- 파일로부터 라이브러리를 설치하기 위함.
Google Drive Colagoratory
https://colab.research.google.com/
- 구글에서 제공하는 주피터노트북이라고 생각하면 됨! : 머신러닝을 위한 가상환경
- 구글 드라이브의 확장 프로그램
- 간단한 메뉴만으로 무료 GPU 사용 가능
- 다른사람과 실시간 협업
- python 2와 3사용가능
* 구글 로그인을 하여 사용하기
깃허브 : 소스코드에 대한 버전관리 및 협업플랫폼
- 깃허브에 업로드된 쥬피너노트북 파일을 바로 Colab에서 확인하는 방법
- https://github.com 를 https://colab.research.google.com/github로 바꾸면 가능.
- 가끔 너무 크거나 그러면 안 열림 : 파일이 궁금하면 다운로드를 받아서 켜면 가능
- Open in Colab (크롬 확장프로그램) @ https://j.mp/2YCcuDs을 사용하면 됨
- 코드를 복사해서 바로 끌고 갈 수 있다. - 깃허브에 업로드된 각종 파일을 바로 visual studio code를 수정, 확인하려면
- 깃허브에 로그인 필수
- https://github.com 을 https://github.dev으로 고치면 가능
Part2. 파이썬 정형 데이터 분석 & 데이터 시각화
데이터를 수집하기 위한 방법
- 다양한 데이터 inflow(수집방법)
- Questionnaire : 설문지
- User interation & User activity (CRUD)
- Sensor data (IOT) - 다양한 데이터 타입
- Structed data : 정형데이터, 엑셀파일(행렬로 정제된 데이터), Relational Database, Spread sheets
: 딥러닝 모델보다, 전통적인 머신러닝이 조금 더 좋은 결과를 보여줌
- Semi stuctured data : System logs, Sensor data, HTML 데이터
: 반정형, 구조는 있으나, 바로 정형하기 힘든 데이터
: 비정형 데이터의 텍스트의 일종으로 볼 수 있음
- Unstructed data : 이미지, 비디오, 사운드, 문서
: 일상생활에서 많이 만나는 데이터
: 수치행렬을 통해서 정형데이터로 바꾸어서 할 수 있다. - 다양한 데이터의 collection - owned data
- 다양한 툴 모두 가능하다
: google analytics : 웹사이트, 앱 의 트랙픽 분석과 사용자 행동을 이해하기 유용
- 마케팅 직군에서 많이 사용됨
: Elastic stack or ELK Stack : 로그 및 데이터 분석을 위한 오픈 소스 도구 모음(3가지를 묶어서 ELK라고 부름)
- Logstash : 데이터를 수집, 처리, 변환하여 Elasticsearch로 보내는 데이터 파이프라인.
- Elasticsearch : 데이터를 저장하고 검색 및 분석하는 분산 검색 엔진.
- Kibana : Elasticsearch에서 시각화된 데이터를 보여주는 대시보드 도구. ELK의 꽃,
+ 추가된 것 : Beats : 경량 데이터 수집기, 다양한 데이터를 Elastic Stack으로 보내는 역할.
* 유튜브에서 Elastic 한국사용자그룹에서 튜토리얼 보기
: Zeppelin : 데이터 탐색과 시각화를 위한 오픈 소스 웹 기반 노트북
- 여러 프로그래밍 언어(예: SQL, Python, Scala, R 등)를 지원 - 다양한 데이터의 collection - unowned data
- APIs (Twitter, Facebook, Instagram 등)
: API를 사용한다는 말 : 애플리케이션 간의 데이터를 주고받거나 기능을 상호작용하도록 하기 위해 특정한 규칙을 통해 통신하는 것 : 이게 없으면, 서버가 다운되는 문제가 생길 가능성이 큼.
: 웹에서의 API : 웹을 통해 애플리케이션이 데이터를 주고받을 수 있도록 설계된 인터페이스
: 오픈 이유 :
* 공익적인목적(기상청, 통계청, 질병관리본부등)
* API를 쓸 수록 수익이 나는 경우(업비트)
* SNS 서비스(web 크롤링의 타겟) : 유저기호파악등을 위하여
- Bots (Web crawler, Web scraper)
: 원하는 데이터를 가져올 수 있음
: 저작권 문제..주의하기 : 야놀자-여기어때/링크드인 -> 하지만 긁어간쪽이 이김 : 어차피 공개된 데이터이다.라는 판결
: 프로젝트 용도, 공부적 용도는 괜찮지만, 사업적인 용도는 주의하기.
: 입사시에도 크롤링 기반의 회사는 주의하기
* 웹크롤링은 확장프로그램등이 많음 : Listly , ScrapeStorm, Octoparse, Automatio 등
- 다양한 데이터의 collection - Public data & Open data (APIs & files)
- 공공 데이터 포털 : https://www.data.go.kr/
- 국가 통계 포털 : https://kosis.kr/index/index.do
- MDIS (MicroData Integrated Servies) : https://mdis.kostat.go.kr/index.do
*오픈 API를 통한 공공데이터 수집을 할 수 있어야함. - 다양한 데이터의 collection - 그 외 (데이터셋, 데이터 repository)
- Awesom Public Dataset : https://github.com/awesomedata/awesome-public-datasets
- Google AI Datasets : https://research.google/resources/datasets/
- Google Dataset Search : https://datasetsearch.research.google.com/
- Kaggle competition datasets : https://www.kaggle.com/competitions
- 데이터온 : https://dataon.kisti.re.kr/
- AI 오픈이노베이션 허브 : https://www.aihub.or.kr/
- 금융결제원 오픈 API 통합포탈 : https://openapi.kftc.or.kr/main
- 서울시 우리마을가게 상권분석 서비스 : https://golmok.seoul.go.kr/main.do
- 서울 열린 데이터 광장 : https://data.seoul.go.kr/
- 19 places to find free data sets : https://www.dataquest.io/blog/free-datasets-for-projects/
- a comprehensive list of open data : https://dataportals.org/
- datasets for data mining/science : https://www.inf.ed.ac.uk/teaching/courses/dme/html/datasets0405.html
파이썬 라이브러리 실습
데이터 분석시에 가장 많이 사용되는 라이브러리 3가지
import numpy as np
import pandas as pd
import seaborn as sns
파일을 읽을때 read 계열의 함수를 쓰기 : read+tab을 하면 여러가지가 뜨고 파일에 맞춰서 쓰면 됨
# 엑셀 파일 읽기
df = pd.read_excel('animals.xlsx')
# with open('animals.xlsx', mode="r", encoding="utf-8") as file:
# df = pd.read_excel(file)
데이터프레임
- 데이터 프레임 불러오기
- 자동으로 만들 때, 맨 앞에 숫자가 들어감 : index 열 : 목록으로 보면 됨
df
# index 열 (행이름 열)
# df.set_index('name')
- 인덱스열을 따로 지정하지 않아서 생긴 일 : 인덱스열을 다시 지정할 수 있음

- head 함수 : df.head()
- 앞에 5개 불러오기 - tail 함수 : df.tail()
- 맨 뒤에 5개 불러오기 - describe 함수 : df.describe()
- 기술 통계량 == Descriptive Statistics : # describe = 묘사하다.
- 데이터에 대해서 설명을 할 수 있게 도와주는. 요약을 해서 보여주는 통계치
- 개수, 평균, 표준편차, 최대, 최소, 사분위수(quantile)를 보여줌 - info 함수 : df.info()

101 non-null : 101개의 데이터가 빠져있는 값이 없다는 의미
int 64 : 비트수, 64비트의 정수를 의미. 64비트(데이터가 저장될때 사용되는 공간)
- 데이터가 너무 많아지면 비트수를 떨어뜨릴 때도 있음 : 계산속도 개선을 위하여
- null 빠져있는 값. : 미싱데이터
non-null <- null == NoneType == None == 無 == N/A (not availabe) == NAN (Not a number)
- 결측치(missing data)를 다루는 대표적인 방법
(ex. 보험 가입 고객들에 대한 데이터 中 나이(age)열에 일부 데이터가 빠져있을 때)
- 랜덤하게 채워넣기
- 주변 (행의) 값들로 채워넣기 : 시계열 데이터의 경우(ex, 시계열로 온도데이터를 받아오는데 중간이 빠질경우)
- 열의 대푯값을 계산해서 채워넣기 (mean 평균 , median중윗값, mode 최빈값)
- 전체 행들을 그룹으로 묶어낸 후 그룹 내 해당 열의 대푯값으로 채워넣기 : 가장 좋은 방법
- 나머지 열들로 머신러닝 예측모델을 만든 후 해당 열의 값을 예측해 채워넣기
- 특정 기준 비율 이상으로 빠져있을 시 해당 열 삭제
- 열단위로 출력하기
- 하나의 열 출력하기
df['name'].head() #부르고 싶은 열 이름 적기
- 여러개의 열 출력하기
df[['name', 'hair', 'feathers']].head() # 부르고 싶은 열 모두 적기- 대괄호를 꼭 2번 써줘야함 : 써주지 않으면 keyerror가 뜸
데이터 프레임 다루기
- 기존 df 에서 일부 열의 데이터를 이용하여 새로운 열을 만들기
- hair 열에 1을 더한 새로운 열을 new_hair 로 추가하기
- 아래 세 방법 모두 동일한 내용의 코드. 하지만 코드 내용이 다름
new_hair = []
for item in df_new['hair']:
new_hair.append(item + 1)
df_new['new_hair'] = new_hairdef plus_one(x):
return x + 1
df_new['new_hair'] = df_new['hair'].apply(plus_one)df_new['new_hair'] = df_new['hair'].apply(lambda x : x + 1) # '적용하다' 를 영어로?
df_new.head()- 가장 짧고 어려운 함수/ lamda를 사용함
- Type 을 index 로 하는 새로운 df 만들기 (엑셀의 pivot table 과 유사)
- pivot : 방향을 튼다, 방향을 틀어서 저장하는 것
pivot_df = pd.pivot_table(df_new, index='type', aggfunc=np.sum)- 타입이 각각 1,2,3,4,....인 것을 모아 둔 것

- aggfunc : Aggregating function (집계 함수)
: 각각에 대해서 어떤 연산을 적용한 것인가?에 대한 것, sum을 적용했으니 -> 합친것
: 타입이 1인 값들의 hair열에 있는 모든 것을 합쳤다!라는 의미.
: 집계함수는 필요에 의해서 쓰면 됨, 합계/평균 등등
- 지우기
- 열지우기
del pivot_df['new_hair'] # '삭제하다'의 앞 3글자
pivot_df
-행지우기
pivot_df = pivot_df.drop([3]) # Database 에서 data point 를 drop!
pivot_df
pivot_df = pivot_df.drop(['다', '가', '사']) # 지우고 싶은게 많으면 여러개를 동시에 지워도 괜찮음
- 행이름 열이름 불러오기
- 행이름 불러오기 (컬럼의 이름)
pivot_df.columns
- 열이름 불러오기 (인덱스 이름)
pivot_df.index
- 열이름 바꾸기
pivot_df.rename(columns = {'eggs':'산란',
'feathers':'깃털'}, inplace=True) # inplace 옵션 == 덮어쓰기 여부
pivot_df.head()리스트는 조심성이 없어서, 리스트는 덮어쓰는 걸 바로 가능.
하지만 데이터프레임같은 경우는 원본은 안 바뀌기에 : 동일한 이름의 데이터프레임으로 덮어쓰기나 다른이름으로 저장해야함
- rename 뒤에 shift+tab을 하면 바뀜
- 그게 아니라면, inplace 옵션으로 하여 덮어쓰기를 하기
- 어떤 열을 기준으로 정렬하기
- 산란수를 기준으로 정렬하기
pivot_df.sort_values(by='산란', inplace=True) # 내용(value)을 기준으로 정렬(sort), inplace=True : 덮어쓰기
pivot_df.head()
- 내림차수 정렬
pivot_df.sort_values(by='산란', ascending=False, inplace=True)
pivot_df.head()- ascending : 올라가는 방향 -> 역순으로 정렬
- 만약 문제가 있다면 shift+tab으로 열어보고 확인하기
- 복사하기
# 얕은 복사와 깊은 복사
pivot_df_2 = pivot_df # shallow copy
pivot_df_3 = pivot_df.copy() # deep=True, deep copy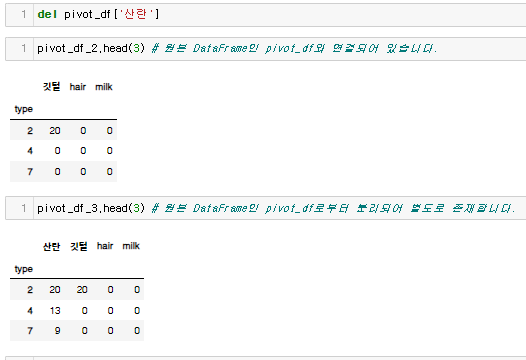
- 2는 똑같은 메모리상에 되어있는데, 명명만 하나 더 생긴거 완전히 똑같은 것
- 3은 데이터 프레임이 완전히 별개 된 것. 완전히 카피가 된 것
파이썬 통계자료 분석 및 시각화 실습
0. 라이브러리 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # rc == run configure(configuration file)
1. 데이터 입력 및 데이터 전처리
- 원하는 엑셀파일 불러오기
df = pd.read_excel('관서별 5대범죄 발생 및 검거.xlsx') # 엑셀 파일 읽기
- 각각의 관서를 구별로 정렬하기
- 비교를 하고 싶은 것을 묶는 것. : 구에 대한 정보를 담은 것을 만들어주는 것
- 서울시 경찰청의 소속 구 @ https://goo.gl/MQSqXX
police_to_gu = {'서대문서': '서대문구', '수서서': '강남구', '강서서': '강서구', '서초서': '서초구',
'서부서': '은평구', '중부서': '중구', '종로서': '종로구', '남대문서': '중구',
'혜화서': '종로구', '용산서': '용산구', '성북서': '성북구', '동대문서': '동대문구',
'마포서': '마포구', '영등포서': '영등포구', '성동서': '성동구', '동작서': '동작구',
'광진서': '광진구', '강북서': '강북구', '금천서': '금천구', '중랑서': '중랑구',
'강남서': '강남구', '관악서': '관악구', '강동서': '강동구', '종암서': '성북구',
'구로서': '구로구', '양천서': '양천구', '송파서': '송파구', '노원서': '노원구',
'방배서': '서초구', '은평서': '은평구', '도봉서': '도봉구'}
df['구별'] = df['관서명'].apply(lambda x: police_to_gu.get(x, '구 없음')) # 적용하다?
df.head()
- dict[칼럼명].apply(칼럼 내 데이터마다 적용할 함수) : police_to_gu.getrk dict이다.
- dict.get(key)는 value 를 return : 없는 get을 바로 알기 위해서
- 가장 앞에 구이름을 넣어주기
- set_index로 쓰면 구가 중복인 경우에는중복되어서 됨
df.set_index('구별')
- 구 중복이 없으려면, 피벗테이블을 써야한다.
gu_df = pd.pivot_table(df, index='구별', aggfunc=np.sum)
gu_df - 관서별 데이터를 구별 데이터로 변경 (index : 관서 이름 -> 구 이름, column은 자동으로 오름차순 정렬됨)
- 같은 구의 경우에는 sum 을 적용
- 구가 없는 열 삭제하기
gu_df = gu_df.drop(['구 없음'])
gu_df# df.drop([row]) : 해당 행 데이터를 drop == DB 에서 특정 데이터를 drop 하는 것과 동일
- 범죄별 검거율 계산하기
gu_df['강간검거율'] = gu_df['강간(검거)']/gu_df['강간(발생)']*100
gu_df['강도검거율'] = gu_df['강도(검거)']/gu_df['강도(발생)']*100
gu_df['살인검거율'] = gu_df['살인(검거)']/gu_df['살인(발생)']*100
gu_df['절도검거율'] = gu_df['절도(검거)']/gu_df['절도(발생)']*100
gu_df['폭력검거율'] = gu_df['폭력(검거)']/gu_df['폭력(발생)']*100
gu_df['검거율'] = gu_df['소계(검거)']/gu_df['소계(발생)']*100
gu_df.head()- 필요없는 column 지우기 (범죄별 발생 건수와 검거율만 남긴다)
del gu_df['강간(검거)']
del gu_df['강도(검거)']
del gu_df['살인(검거)']
del gu_df['절도(검거)']
del gu_df['폭력(검거)']
del gu_df['소계(발생)']
del gu_df['소계(검거)']
- df.drop(['row']) : 해당 행 데이터를 drop
- del df['column'] : 해당 열 데이터를 drop
- 여러 줄을 한번에 수정할 때 : ctrl을 누르고 클릭을 통해서 멀티커서를 만들어보기
- ctrl + / : 주석을 풀었더 넣었다 하는 단축키
- 하나를 타겟해서 보는 코드
gu_df.at['강남구', '검거율']- masking 기법
gu_df[ gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100 ] = 100
gu_df.head(10)
-> 100이 넘으면 100으로 취급하는 것gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100
-> true나 false로만 나오는 데이터프레임이 만들어짐
- filtering 적용 : 자주 쓰는 코드, 기억해야함. -masking이랑 비슷한데, 다른내용
gu_df[ gu_df['살인(발생)']>7 ] # 살인사건 발생 건수가 7건이 넘는 지역구를 추려기
gu_df[ (gu_df['살인(발생)']>7) & (gu_df['폭력(발생)']>2000)] # 살인사건 발생 건수가 7건이 넘고(and) 폭력사건 발생 건수가 2000건을 넘는 지역구
gu_df[ ~(gu_df['살인(발생)']>5) ] # 살인사건 발생 건수가 5건을 넘지 않는(not) 지역구
- 열이름 기준으로, 필터 기준을 넣어야함.
- 열이름 앞에 데이터프레임을 적어줘야 열을 꺼내주는 것이다. 이름을 꼭 적어주고 괄호 잘 치기.
- 이 부분에서는 영어 연산자가 먹히지 않아서 비트논리 연산자를 사용해줘야함
and = &
or = | (shift + 키보드 ₩))
not = ~
- NaN (not a number, 결측치의 일종)을 없애주기
- 검거율 계산 시 0으로 나누는 계산으로 인해 생김
- 살인검거율' 열의 결측치를 100으로 채워주기
gu_df['살인검거율'] = gu_df['살인검거율'].fillna(100)- 결측치(N/A)의 값을 채워주다(fill)
- 이름을 새로 지어주기
gu_df.rename(columns = {'강간(발생)':'강간',
'강도(발생)':'강도',
'살인(발생)':'살인',
'절도(발생)':'절도',
'폭력(발생)':'폭력'}, inplace=True) # inplace 옵션 == 덮어쓰기 여부
gu_df.head()
- 인구 데이터와 합쳐주기
- cvs파일 읽기
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8') # read_csv 는 encoding 옵션을 직접 지정해줄 수 있습니다. (utf-8, euc-kr, cp949)
popul_df.head()- 인코딩을 할 때, utf-8방식으로 하겠다 임 : utf-8이 안되면, cp949랑 euc-kr : 인코딩 약속체계 종류
A & B : 데이터프레임
- C = A.join(B) <- A & B 데이터프레임의 index 열이 동일해야 함 : 열이름 각각 해서 하는 것
- C = pd.merge(A, B, left_on='구별', right_on='구 이름', how='inner') : 구별에 맞추어서 넣을 수 있음
- C = pd.concat([A, B], axis=1) : 막 붙이는 것

- index를 기준으로 merge를 하기 위해, index 세팅하기
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8', index_col='구별')# 아래와 같이 먼저 read_csv()로 읽어들이고 .set_index()를 적용할 수도 있습니다.
# popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8').set_index('구별')
# 구별 index 를 기준으로 merge를 할 것이므로, index 를 세팅해주기
- 데이터 프레임 의 M&A
gu_df = gu_df.join(popul_df)
gu_df.head()# df1.join(df2) : df1 의 index를 기준으로 df2 의 index 중 매칭되는 값을 매김
2. 데이터 탐색 : 전처리와 시각화
- 데이터 살펴보기
gu_df.sort_values(by='검거율', ascending=False, inplace=True) # ascending=False : 내림차순, inplace=True : 덮어쓰기
gu_df.head()# 검거율 기준으로 오름차순 정렬하기
# '값'을 기준으로 정렬할 때?
- 히트맵으로 시각화
import seaborn as sns
sns.heatmap(gu_df[['강간', '강도', '살인', '절도', '폭력']])
-> 문제 1. 한글 폰드가 모두 깨짐
-한글 데이터 시각화를 위한 준비
# jupyter notebook 내에 figure를 보여주기
%matplotlib inline
# matplotlib의 한글문제를 해결
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
# font_name
rc('font', family=font_name)
## Mac OS
# rc('font', family="AppleGothic")
- rc : run configure(configuration file)의 줄임말, 리눅스에서 온 말 -> 폰트로 세팅을 해주는 코드

- 폰트가 안 깨짐
-> 문제 2 : 각각의 크기에 따라서 엄청 크기가 다름 : / 범죄별 발생 건수가 정규화가 되어있지 않음 : 위아래 비교가 안되고 전체 비교가 됨
- 건수 정규화 하기 : 각열의 최대값으로 열을 나눠줄것이다
: 최대값으로 나눠줌
weight_col = gu_df[['강간', '강도', '살인', '절도', '폭력']].max()
weight_col
- 최댓값을 끌어내는 함수
crime_count_norm = gu_df[['강간', '강도', '살인', '절도', '폭력']] / weight_col
crime_count_normB = A / A.max()
B = A * A.mean()
- 최댓값으로 각각을 나눠주기
crime_count_norm = gu_df[['강간', '강도', '살인', '절도', '폭력']] / weight_col
crime_count_norm- 내림차순으로 정렬 하고 다시 그래프 보여주기
sns.heatmap(crime_count_norm.sort_values(by='살인', ascending=False)) # 내림차순으로 정렬하려면?
- 문제 : 안에 글씨가 보였으면 좋겠다 + 크기가 작아서 생략되는 부분이 있다.
# 몇 가지 옵션으로 더 내용을 확인하기 편하도록 수정하기
# 전체 figure 의 사이즈를 조정
plt.figure(figsize = (10, 10))
# annot : 셀 내에 수치 입력 여부
# fmt : 셀 내 입력될 수치의 format (f == float)
# linewidths : 셀 간 이격거리 (하얀 부분, 내부 테두리)
# cmap : matplotlib colormap @ https://goo.gl/YWpBES
sns.heatmap(crime_count_norm.sort_values(by='살인', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(살인발생으로 정렬) - 각 항목별 최대값으로 나눠 정규화')
plt.show()- plt.figure : 도화지를 여는 코드 -> 크기를 줄이고 늘릴 수 있음
- plt.show() : 표를 보여주는 것
- annot : 셀 내에 수치 입력 여부
- fmt : 셀 내 입력될 수치의 format (f == float)
- linewidths : 셀 간 이격거리 (하얀 부분, 내부 테두리)
- cmap : matplotlib colormap @ https://goo.gl/YWpBES : 색상표, 원하는 걸 선택해서 넣으면 됨

- 인구수 넣기 (위에서 진행했으나, 진행순서를 확인하기 위해서 한번 더 적어둠)
- csv 파일 읽어오기
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8') # read_csv 는 encoding 옵션을 직접 지정해줄 수 있습니다. (utf-8, euc-kr, cp949)
popul_df.head()# 구별 index 를 기준으로 merge를 할 것이므로, index 를 세팅해주기
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8', index_col='구별')
popul_df.head()
# 아래와 같이 먼저 read_csv()로 읽어들이고 .set_index()를 적용할 수도 있습니다.
# popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8').set_index('구별')# 데이터프레임의 M&A
gu_df = gu_df.join(popul_df) # df1.join(df2) : df1 의 index를 기준으로 df2 의 index 중 매칭되는 값을 매김
gu_df.head()
- (단순히 범죄건수만 보지 말고) 인구수로 나눠서 인구대비 발생비율로 살펴보기
crime_count_norm.head(3)# 행(구)별로 구별 범죄 수 (max 대비 비율값) / 구별 인구 수 * 100000
# 인구 수 단위인 10만을 곱해준다 (강서구 강간 = 9.795665e-07 -> 0.x 까지 끌어올리기)
crime_ratio = crime_count_norm.div(gu_df['인구수'], axis=0) * 100000
crime_ratio.head()C = A.div(B['열이름'], axis=0)
axis = 0 : 열방향 연산 / axis = 1 : 행방향 연산
crime_count_norm['강도'] = crime_count_norm['강도'] / gu_df['인구수']
- 인구수 대비 구별 살인 발생 순위 살펴보기
plt.figure(figsize = (10,10))
sns.heatmap(crime_ratio.sort_values(by='살인', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(살인발생으로 정렬) - 각 항목을 정규화한 후 인구로 나눔')
plt.show()
- 인구수 대비 5대 범죄 발생 수치 평균
# 구별 인구 대비
crime_ratio['전체발생비율'] = crime_ratio.?(axis=1) # 평균?
crime_ratio.head()
plt.figure(figsize = (10,10))
sns.heatmap(crime_ratio.sort_values(by='전체발생비율', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(전체발생비율로 정렬) - 각 항목을 정규화한 후 인구로 나눔')
plt.show()
3. 데이터 시각화 : 지도 시각화
- 데이터 시각화의 코드를 얻을 수 있는 사이트 : https://python-graph-gallery.com/
!pip install folium==0.5.0- 지도 시각화 : Folium library 을 활용합니다.
- 지도 데이터 : https://github.com/southkorea/southkorea-maps 에서 서울만 따로 추린 GeoJSON 데이터를 활용합니다
(southkorea-maps/kostat/2013/json/skorea_municipalities_geo_simple.json) : json에 담겨있는 것을 보여줌
- 해상도 : 각각 다르게 준비가 되어있음, 시각화 단위별로 결정해서 하면 됨

- GeoJSON : JSON 데이터 형식을 활용한 공간 데이터 교환 포맷(Geospatial Data Interchange Format)
- GeoJSON에서 Feature는 Geometry object와 속성정보를 담고 있고, Feature 컬렉션은 Feature의 집합으로 구성됩니다.
- 상세 정보 링크 : https://goo.gl/GL2F2w & https://goo.gl/E4NCLC
- Folium library 설치 :
- pip install folium==0.5.0
- pip install --index-url=http://pypi.python.org/simple/ --trusted-host pypi.python.org folium==0.5.0
- conda install folium==0.5.0
# import warnings
# warnings.simplefilter(action = "ignore", category = FutureWarning)
import json
geo_path = 'skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))-json 함수에게 넘겨주면, 파일을 열 수 잇게 됨.
- json은 파이썬 기준으로 dict(딕션러니) 형식이다
- Javascript Object Notaion의 줄임말이다.
- 데이터 교환 표준 포멧이다.
geo_str['features'][0]- json은 파이썬 기준으로 dict(딕션러니) 형식이다
{'type': 'Feature', 'id': '강동구','properties':
{'code': '11250', 'name': '강동구', 'name_eng': 'Gangdong-gu', 'base_year': '2013'},
'geometry': {'type': 'Polygon', 'coordinates': [[[127.11519584981606, 37.557533180704915], [127.16683184366129, 37.57672487388627], [127.18408792330152, 37.55814280369575], [127.16530984307447, 37.54221851258693], [127.14672806823502, 37.51415680680291], [127.12123165719615, 37.52528270089], [127.1116764203608, 37.540669955324965], [127.11519584981606, 37.557533180704915]]]}}
- 자바 서버에서 파이썬 서버로 (서로다른 언어로 주고받을때) 대화가 통해야한다.
- 그래서 만들어진 코드이다.
지도를 그리기
import folium
# tiles : 지도 타입 (default type or "Stamen Terrain" or "Stamen Toner")
# location : 초기 지도 center 위치
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Cartodb Positron') # Stamen Toner->Cartodb Positron으로 바꿈
map
구별 살인사건 발생 건수 시각화
# 살인사건 발생건수 시각화
# Choropleth map : 정의 @ https://goo.gl/yrTRHU, folium 공식문서 @ https://goo.gl/5UgneX
# Another available library for Choropleth map : Altair @ https://altair-viz.github.io/gallery/choropleth.html
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
map.choropleth(geo_data = geo_str, # 서울시 행정구역별 polygon drawing
data = gu_df['살인'], # 시각화의 대상이 될 데이터
columns = [gu_df.index, gu_df['살인']], # 1) df의 index 칼럼을 가져와 인식하고
fill_color = 'PuRd', #PuRd, YlGnBu <- color brewer (http://colorbrewer2.org/) : ‘BuGn’, ‘BuPu’, ‘GnBu’, ‘OrRd’, ‘PuBu’, ‘PuBuGn’, ‘PuRd’, ‘RdPu’, ‘YlGn’, ‘YlGnBu’, ‘YlOrBr’, and ‘YlOrRd’
key_on = 'feature.id') # GeoJSON 규약을 따름, json 파일(지도 데이터)의 "feature" type의 "id" 에 매칭된다
map# key_on: Variable in the GeoJSON file to bind the data to.
# Must always start with 'feature' and be in JavaScript objection notation.
# Ex: 'feature.id' or 'feature.properties.statename'.

- state election results
인구수 대비 기준 구별 데이터 시각화
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Stamen Toner')
# 전체 5대 범죄 인구당 발생비율 시각화
map.choropleth(geo_data = geo_str,
data = crime_ratio['전체발생비율'],
columns = [crime_ratio.index, crime_ratio['전체발생비율']],
fill_color = 'PuRd', #PuRd, YlGnBu
key_on = 'feature.id')
map
구별 검거율 데이터 시각화
map = folium.Map(location=[37.5502, 126.982], zoom_start=11, tiles='Cartodb Positron')
# 검거율 시각화
map.choropleth(geo_data= geo_str,
data = gu_df['검거율'], # 검거율로 시각화하려면?
columns = [gu_df.index, gu_df['검거율']],
fill_color = 'YlGnBu', #PuRd, YlGnBu (Yellow, Green, Blue)
key_on = 'feature.id')
map
저장하기
1. jpg로 저장하기
plt.savefig('example.jpg')
2. html로 저장하기
# Saving a folium map as an HTML file
map.save('folium_map.html')
3. database 저장하기
DF to csv file
gu_df.to_csv('processed_data.csv', encoding='utf-8') # 혹은 euc-kr or cp949
추가공부 파일 확인
- ppt에 있는 각각의 라이브러리 확인하기
* 가장 권장되는 라이브러리 : LUX (DataFrame-based 자동 데이터시각화 라이브러리 + Altair)
- https://j.mp/3aoFhSe & https://j.mp/2LMAK1L
- 파이썬 기반의 데이터 분석가 : pandas가 가장 중요하다.
<p data-ke-size="size16"
요약정리
2. 파이썬 기초 함수
-5. Python 기본 내장함수와 외장함수
- : 의 기능 -> index number 기준 범위 지정시, multi -line code block, dict (key & value), lamba function : lamba
-6. 라이브러리 활용하기
- Code가 길어지면, 코드를 보기 힘들어짐->유지보수가 힘들어짐
- 단일.py = module : 이 module을 모아둔 것이 library = Package
- 라이브러리를 설치하기 (pip install/conda install을 사용)
- 라이브러리 가져와서 사용하기 : import를 이용하여 불러오기, as를 활용하여 별명붙이기
- Google Drive Colagoratory
- 깃허브 활용하기
Part2. 파이썬 정형 데이터 분석 & 데이터 시각화
- 데이터를 수집하기 위한 방법
다양한 데이터 inflow(수집방법) : 설문지, CRUD, IOT
다양한 데이터 타입 : 정형, 반정형, 비정형
다양한 데이터의 collection - owned data : google analytics, ELK Stack, Kibana
다양한 데이터의 collection - unowned data : APIs, Bots
다양한 데이터의 collection - Public data & Open data (APIs & files)
다양한 데이터의 collection - 그 외 (데이터셋, 데이터 repository) - 파이썬 라이브러리 실습
데이터프레임
- 인덱스 열 지정
- 함수 : head, tail, describe, info
- lamda 함수 - 파이썬 통계자료 분석 및 시각화 실습
0. 라이브러리 불러오기
1. 데이터 입력 및 데이터 전처리
- 원하는 엑셀파일 불러오기
- 각각의 관서를 구별로 정렬하기
- 가장 앞에 구이름을 넣어주기
- 구가 없는 열 삭제하기
- 범죄별 검거율 계산하기
- 필요없는 column 지우기 (범죄별 발생 건수와 검거율만 남긴다)
- masking 기법
- filtering 적용 : 자주 쓰는 코드, 기억해야함. -masking이랑 비슷한데, 다른내용
- NaN (not a number, 결측치의 일종)을 없애주기
2. 데이터 탐색 : 전처리와 시각화
- 데이터 살펴보기
- 히트맵으로 시각화
- 한글 데이터 시각화를 위한 준비
- 건수 정규화 하기 : 각열의 최대값으로 열을 나눠줄것이다
- 인구수 넣기
3. 데이터 시각화 : 지도 시각화
- Folium library 설치 :
- 지도를 그리기
- 구별 살인사건 발생 건수 시각화
- 인구수 대비 기준 구별 데이터 시각화
- 구별 검거율 데이터 시각화
4. 저장하기
- jpg로 저장하기
- html로 저장하기
- database 저장하기
부족한 부분 추가 공부할 부분
함수 관련은 사용을 많이 하여서 괜찮다고 생각이 되나, 컨테이너 부분에 대한 추가적인 이해가 필요한 것 같다.
이해는 되나, 실사용에서 어려움을 느낄 수도 있다고 생각됨.
파이썬 함수에 대해서 조금 더 이론적인 공부가 더 필요하다고 생각됨.
- 실사용보다는 함수에 대한 실질적인 이해
비슷한 예시의 플랫을 만들어 보는 것이 중요함.
- 실전 연습이 다수로 진행되어 함수와 라이브러리를 익히는 과정이 필요해보임
'Upstage AI LAB 부트캠프 5기 > 실시간 공부내용 복습' 카테고리의 다른 글
| [2024.10.07] Statistics 기초 강의 (2) | 2024.10.07 |
|---|---|
| [2024.10.04] 파이썬 프로그래밍 이해하기 (8) | 2024.10.04 |
| [2024.10.01] 파이썬 프로그래밍 이해하기 (9) | 2024.10.02 |
| [2024.09.30] 파이썬 프로그래밍 이해하기 (10) | 2024.09.30 |
| [2024.09.24] Python 기초 강의 공부 내용 정리 (6) | 2024.09.24 |