[2024.09.27] 필수 온라인 강의 Part2 파이썬 라이브러리 활용 CH02 수치계산라이브러리(NumPy)
Numpy
- 수치계산 라이브러리 : 파이썬 기반 수치 해석 라이브러리
- numerical Python의 약자
- 선형대수 연산에 필요한 다차원 배열과 배열 연산을 수행하는 다양한 함수 제공
- https://numpy.org/ 참고하기
- 설치 방법 : pip install numpy : colab에서는 설치는 안해도 괜찮음
- 사용방법 : import numpy as np
- numpy에서 배열은 ndarrary 또는 array 라고 부름
- numpy.array와 python.array는 다름 : numpy array가 python list에 비해 문법이 간단하고 성능이 뛰어나다
- numpy array : [1,2,3] +[ 1,2,3 ] = [2, 4, 6]
- python.array : [1,2,3] +[ 1,2,3 ] = [ 1,2,3 , 1, 2,3 ]
- numpy array : [1,2,3] +1 = [2, 3, 4]
- python.array : [1,2,3] *2= [ 1,2,3 , 1, 2,3 ]
- Numpy 배열
- numpy는 모든 배열의 값이 기본적으로 같은 타입
- numpy에서 각 차원(Dimension)을 축(axis) 라고 표현


- 1,2,3차원의 배열 : 차원만큼 축이 있음
[1, 2, 1]- 아래와 같은 데이터는 1개의 축을 가지며,
- 축은 3가지 요소(element)를 가지고 있다고 하고 길이(length)는 3이다.
[[ 1, 0, 0], [ 0, 1, 2]]- 아래와 같은 데이터는 2개의 축을 가지며,
- 첫 번째 축은 길이가 2이고 두 번째 축은 길이가 3이다.
- Numpy 배열 대표 속성값
- ndarray.shape : 배열의 각 축(axis)의 크기
- ndarray.ndim : 축의 개수(Dimension)
- ndarray.dtype : 각 요소(Element)의 타입
- ndarray.itemsize : 각 요소(Element)의 타입의 bytes 크기
- ndarray.size : 전체 요소(Element)의 개수

a = np.arange(12).reshape(3, 4) # a라는 변수에 (3, 4) 크기의 2D 배열을 생성
print(a)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
print(a.shape) -> (3, 4) # ndarray.shape : 배열의 각 축(axis)의 크기
print(a.dtype) -> int 64 # ndarray.dtype : 각 요소(Element)의 타입, 운영체제따라 달라질 수 있음
print(a.itemsize) -> 8 # ndarray.itemsize : 각 요소(Element)의 타입의 bytes 크기
print(a.size) ->12 # ndarray.size : 전체 요소(Element)의 개수
- NumPy 배열 생성
- np.array를 이용하여 Python에서 사용하는 Tuple이나 List를 입력으로 numpy.ndarrary를 생성
a = np.array([2,3,4]) # a 배열 생성 & 타입 확인 (정수)
print(a) -> [2 3 4]
print(a.dtype) -> int64
b = np.array([1.2, 3.5, 5.1]) # b 배열 생성 & 타입 확인 (실수)
print(b) -> [1.2 3.5 5.1]
print(b.dtype) -> float64
- 다양한 차원의 데이터를 쉽게 생성가능
- np.zeros(shape) : 0으로 구성된 N차원 배열 생성
- np.ones(shape) : 1로 구성된 N차원 배열 생성
- np.empty(shape) : 초기화되지 않은 N차원 배열 생성
print(np.zeros((3,4))) # (3,4) 크기의 배열을 생성하여 0으로 채움 (2차원)
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
print(np.ones((2,3,4), dtype=np.int64)) # (2,3,4) 크기의 배열을 생성하여 1로 채움 (3차원)
[[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]]
print(np.empty((2,3))) # 초기화 되지 않은 (2,3) 크기의 배열을 생성
[[4.68268305e-310 0.00000000e+000 0.00000000e+000]
[0.00000000e+000 0.00000000e+000 0.00000000e+000]]
- Numpy arange와 linspace 데이터 생성
- np.arange와 np.linspace를 이용하여 연속적인 데이터를 쉽게 생성가능
- np.arange(): N 만큼 차이나는 숫자 생성
- [] 생략가능, 끝 값 포함 안함
- 장점 : step, 범위를 구간, 간격 강조할 때 사용하면 코드 가독성이 올라감
- np.linspace(): N 등분한 숫자 생성
- 처음과 끝 값을 포함, 몇 개로 만들지 매개변수로 줌
- 장점 : 개수 강조할 때, 사용하면 코드 가독성이 올라감
print(np.arange(10, 30, 5)) # 10이상 30미만 까지 5씩 차이나게 생성
[10 15 20 25]
print(np.arange(0, 2, 0.3)) # 0이상 2미만 까지 0.3씩 차이나게 생성
[0. 0.3 0.6 0.9 1.2 1.5 1.8]
x = np.linspace(0, 99, 100) # 0~99까지 100등분
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.
18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35.
36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53.
54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71.
72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. 89.
90. 91. 92. 93. 94. 95. 96. 97. 98. 99.]print(np.arange(0, 1+0.25, 0.25)) # arange 함수는 끝 값을 포함하지 않기 때문에
# 가독성을 위해서 1.25를 1+0.25로 표현!
# 0부터 1.25 미만까지(끝 값 포함 안하니까 1까지 출력) 0.25씩 차이나게 생성
[0. 0.25 0.5 0.75 1. ]
print(np.linspace(0,1,5)) # 위와 동일한 결과를 linspace 함수를 이용하여 코딩
# 0부터 1까지(끝 값 포함) 5등분
- Numpy 배열 출력
- 1D / 2D는 이해 쉬움
- 3D는 이해를 반드시 해야함 : 2차원이 N개 출력되는 형식으로 나타남
c = np.arange(24).reshape(2,3,4) # 3차원 배열 출력
print(c)- (3, 4)크기의 2차원 배열이 2개 출력되는 형식
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
- NumPy 기본 연산
- element wise 연산 : 차원(축)을 기준으로 행렬 내에서 같은 위치에 있는 원소끼리 연산을 하는 방식
- 곱셈이 여러개임
A = np.array( [[1,1],
[0,1]] )
B = np.array( [[2,0],
[3,4]] )
- * : 각각의 원소끼리 곱셈(elementwise produect, Hadamard product)
print(A * B)
[[2 0]
[0 4]]
- @ : 행렬 곱셈(Matrix product)
print(A @ B)
[[5 4]
[3 4]]
- numpy 자동형 변환
- 수치 연산을 진행할 때, 각각의 .dtype이 다르면 타입이 큰 쪽 (int<float<complex)으로 자동으로 변경됨
- numpy 집계함수
- .sum( ) : 모든 요소의 합
- .min( ) : 모든 요소 중 최소값
- .max( ) : 모든 요소 중 최대값
- .argmax( ) : 모든 요소 중 최대값의 인덱스
- .cumsum( ) : 모든 요소의 누적합
a = np.arange(8).reshape(2, 4)**2
print(a.sum()) # 모든 요소의 합
print(a.min()) # 모든 요소 중 최소값
print(a.max()) # 모든 요소 중 최대값
print(a.argmax()) # 모든 요소 중 최대값의 인덱스
print(a.cumsum()) # 모든 요소의 누적합
- numpy 행과 열
- axis = 0 (열기준) , axis = 1 (행기준)

b = np.arange(12).reshape(3, 4) # b 배열 생성 & 출력
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
print(b.sum(axis=0)) # axis = 0은 열 기준으로 연산
[12 15 18 21]
print(b.sum(axis=1)) # axis = 1은 행 기준으로 연산
[ 6 22 38]
- 범용함수
: 필요한 범용함수 : https://numpy.org/doc/1.18/reference/ufuncs.html#available-ufuncs
- 인덱싱 : indexing, 가리킴
- 슬라이싱 : slicing, 잘라냄
- 각각의 문자열에서 한개 또는 여러개를 가리켜서 그 값을 가져오거나 뽑아내는 방법
- 인덱스는 위치값


- numpy boolean 인덱싱 : boolean 타입을 가진 값들로 인덱싱 진행
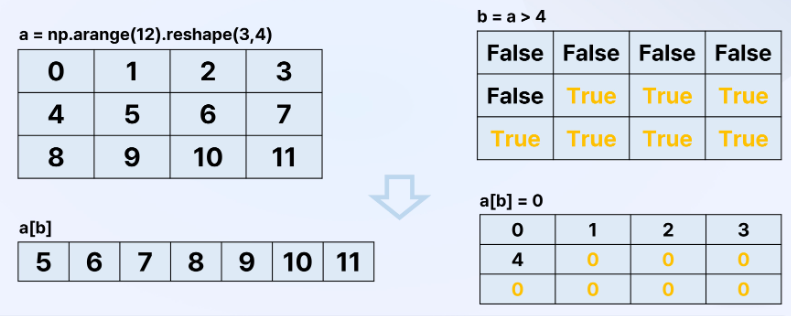
- numpy 크기 변경
: np.ndarrary의 shape을 다양한 방법으로 변경이 가능함
- .ravel : 1차원으로 변경
- .reshape : 지정한 차원으로 변경
- .T : 전치(Transpose) 변환
a = np.arange(12).reshape(3,4) # a 배열 생성 & shape 출력
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
print(a.ravel()) # .ravel : 모든 원소를 1차원으로 변경
[0 1 2 3 4 0 0 0 0 0 0 0]
print(a.reshape(2,6)) # .reshape : 지정한 차원으로 변경
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
print(a.T) # .T : [3,4]의 전치(transpose)변환으로 [4,3] 출력
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
* a = a.T # 만약 전치 형태로 a 배열에 저장하고 싶다면!
- numpy 데이터 합치기
- np.vstack : axis=0(열)기준으로 쌓음
- np.hstack : axis=1(행)기준으로 쌓음

a = np.array([1, 2, 3, 4]).reshape(2, 2) # a 배열 생성 & 출력
[[1 2]
[3 4]]
b = np.array([5, 6, 7, 8]).reshape(2, 2) # b 배열 생성 & 출력
[[5 6]
[7 8]]
print(np.vstack((a,b))) # np.vstack(): axis=0(열) 기준으로 쌓음
[[1 2]
[3 4]
[5 6]
[7 8]]
print(np.hstack((a,b))) # np.hstack(): axis=1(행) 기준으로 쌓음
[[1 2 5 6]
[3 4 7 8]]
- numpy 데이터 쪼개기
- np.hsplit를 통해 숫자 1개가 들어갈 경우 x개로 등분,
- np.hsplit를 통해 리스트로 넣을 경우, axis=1(행) 기준 인덱스로 데이터를 분할

a = np.arange(12).reshape(2, 6) # a 배열 생성 & 출력
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
print(np.hsplit(a, 3)) # [2,6] => [2,2] 데이터 3개로 등분
[array([[0, 1],
[6, 7]]), array([[2, 3],
[8, 9]]), array([[ 4, 5],
[10, 11]])]
print(np.hsplit(a, (3,4))) # [2,6] => [:, :3], [:, 3:4], [:, 4:]로 분할
[array([[0, 1, 2],
[6, 7, 8]]), array([[3],
[9]]), array([[ 4, 5],
[10, 11]])]
'Study > Python' 카테고리의 다른 글
| 파이썬 라이브러리 - Matplotlib (데이터 시각화) (0) | 2024.09.30 |
|---|---|
| 파이썬 라이브러리 - Pandas (데이터 자료 처리 라이브러리) (1) | 2024.09.27 |
| 파이썬 라이브러리 개념 (4) | 2024.09.26 |
| 파이썬_클래스와 모듈 (6) | 2024.09.26 |
| 파이썬 기본기_입출력과 제어문 (4) | 2024.09.26 |