Huggingface - 기계학습을 사용하여 애플리케이션을 구축하기 위한 도구를 개발하는 미국회사 - 2016년 3명의 프랑스 엔지니어에 의해 설립되었으며, 23년 7월 기준 40억달러 이상 - transformers, datasets , spaces …
- transformers 모듈 사용하여 모델/토크나이저 불러오기
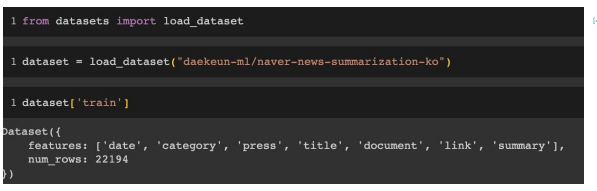
- datasets 모듈 사용하여 데이터셋 불러오기
- 간단하게 pipeline 모듈 사용하여 입력값에 대한 특정 task 수행 가능
대표적인 자연어 처리 Task - 기계 번역 : 다양한 국가의 언어를 원하는 타겟 언어로 번역 - 질의 응답 : 사용자의 질문을 이해하고 관련 문서를 찾아 올바른 정답을 추출하거나 내재된 지식을 통해 생성 - 정보 추출 : 주어진 쿼리를 기반으로 관련 문서, 정보들을 추출 - 감성 분류 : 주어진 입력 문장의 감성 (긍정, 부정, 중립) 을 분류 - 요약 : 주어진 본문의 중요한 내용을 요약
영화 리뷰 감성 분류하기( 감성 분류 Task) - 영화리뷰 데이터를 입력으로 받아 긍정적(1)인지 부정적(0)인지 분류하는 Task - 데이터셋 예시 : nsmc , 네이버 영화리뷰 데이터셋
- Korpora를 통해 데이터셋 읽어오기
- Huggingface Pipeline 활용하여 입출력 확인하기 - 입출력 형태 살펴보기 - 입력(Input) : 문장(str) -> 분류기 모델(Classifier) -> 출력(Output) : 긍부정(int, 0 or 1)
뉴스 본문 요약하기 (요약 Task) - 뉴스 본문 데이터를 입력으로 받아 요약문을 생성하는 Task - 데이터셋 예시 : 네이버 뉴스 요약 데이터셋
- Huggingface datasets 활용하여 데이터셋 읽어오기
- 허깅페이스 Pipeline 활용하여 입출력 확인하기 - 입출력 형태 살펴보기 - 입력 (Input) : 뉴스본문 (document,str) -> 요약 모델 (Summarizer) -> 출력 (Output) : 생성된 요약문 (summary , str)
자연어 처리 평가지표(Evaluation Metrics) - Confusion matrix - 분류 모델의 성능을 평가하기 위해 실제 값과 모델이 예측한 값을 대조하는 표
- Accuracy = TP+TN / (TP+FP+FN+TN) : (모델이) 예측한 것들 중에 (실제와) 일치한 것 비율 - Precision = TP / (TP+FP) : (모델이) 맞았다고 예측한 것 중 (실제로) 맞는 것 비율 - Recall = TP / (TP + FN) : (실제) 맞는 것들 중에 (모델이) 맞았다고 예측한 비율 - F1-score = Precision과 Recall 의 조화평균으로, 두가지 지표를 모두 고려하는 평가지표 - 불균형한 데이터에서 Accuracy 보다 효과적인 평가지표
- FN이 FP보다 더 심각한 실수! : FN(1종 오류), FP(2종오류)
- BLEU (Bilingual Evaluation Understudy Score) - 기계번역 (NMT)이나 텍스트 생성 (Text Generation) 작업의 품질을 평가할때 사용되는 평가지표 (metrics) - 번역 Task에서 정답문장 (reference) 중 몇 단어가 빠져도 (recall 이 떨어져도) 문장의 의미가 유사할 수 있지만, 문장에 없는 단어가 오역되어 들어오면 (precision이 떨어지면) 영향이 클 수 있기 때문에 recall이 아닌 precision을 기반 - n-gram (n = 1~4)의 n값에 따라 문장을 나눠서 정답값(ground truth)과 얼마나 겹치는 지 다각도로 평가
자연어처리 Pipeline
낚시성 기사 탐지 - 뉴스 기사의 제목과 본문을 입력으로 받은 후, 다음 6가지에 해당되는 경우를 분류하는 Task - 데이터셋 : AI_HUB 낚시성 기사 탐지 데이터 활용 (전체 중 비낚시성 : 9,175개 , 낚시성 : 14,390개만 사용)
- 입출력형태 Input : 뉴스 제목 + 뉴스 본문 -> 낚시성 기사 분류 (탐지) 모델 -> Output : 0 (비낚시성) or 1 (낚시성)
파이프라인 전체 구조 1. 환경설정 : 라이브러리 설치 및 데이터셋 로드 (train.csv, test.csv) 2. 데이터셋 구축 : 입력 데이터 (Input data)를 train/valid = 7.5:2.5로 나눠준 (split)후 토크나이징 (Tokenizing)하여 torch dataset class 로 변환 3. 모델 및 토크나이저 가져오기 : Huggingface 의 사전학습된 (Pre-trained) 모델 로드 (load) 4. 모델 학습 : Huggingface 의 TrainingArguments & Trainer 를 활용하여 학습데이터 (train data)로 모델 학습 5. 추론 및 평가 : 학습된 (Fine-tuned) 모델을 통해 평가 데이터 (Test data) 추론 및 평가 (Evaluation)진행
상세 파이프라인 확인하기
데이터 불러오기 - 파일의 확장자에 맞게 pd.dataframe 형태로 로드 - filepath or buffer : 이곳에 csv data 가 위치한 경로 입력 - sep or delimiter : 컬럼을 구분하는 구분자 지정. 기본값은 comma (,) - header : 헤더가 있는 행 번호 지정. 기본적으로 첫번째 행 인식 - usecols : 데이터 읽어올때 사용할 컬럼들 리스트로 지정 - dtype : 각 컬럼의 데이터 타입 지정하는 딕셔너리 - encoding : 문자 인코딩 지정 (e.g) ‘utf-8’ , ‘cp949’)
Pytorch Dataset class - 데이터셋 클래스 (Dataset class)는 우리가 가진 데이터셋을 모델이 정의하고 있는 입력 형태로 가공해주는 클래스 - 데이터셋 클래스를 사용하는 이유 : 효율적인 데이터처리가 가능하고, 확장성/호환성이 좋기 때문
- 다양한 데이터 소스와 형식에 대응하는 DataLoader 구현이 손쉬움 - DataLoader 와 함께 사용하면 배치 학습, 데이터 셔플링, 멀티 프로세싱을 손쉽게 구현가능 - Pytorch 의 다른 구성요소들과 호환성을 유지하면서 구조화된 방식으로 데이터 관리가능
- init (initialization) 초기 데이터 생성/전처리 방법 지정 - len (length) 데이터셋의 전체 길이 반환 - getitem index 에 해당되는 데이터 반환
Tokenizing - Huggingface 에서 사전학습된 토크나이저 불러오기 - 모델 체크포인트 찾기
Model - Huggingface 에서 사전학습된 분류모델 불러오기 - 사전학습된 토크나이저와 모델은 동일한 체크포인트 (checkpoint)여야 학습가능함 - 다른 체크포인트의 토크나이저와 모델을 사용할 시, 호환성 문제 발생
Trainer - Trainer 는 모델을 학습, 평가, 최적화하기 위한 간편하고 확장 가능한 인터페이스를 제공하는 클래스 - Trainer 를 사용하면 배치 학습 (Batch Learning), 학습 스케줄러 (Learning Scheduler) , 학습 조기종료 (EarlyStopping) 등의 기능들을 간단히 사용 가능 - TrainingArguments 옵션 - save_total_limit : 총 몇개의 ckt 를 저장할 것인지 지정하는 인자 - warmup_steps : warmup 을 몇 step 까지 진행할 것인지 지정하는 인자 - warmup이란? 모델의 학습률을 점진적으로 증가시키는 과정 - load_best_model_at_end : 학습 종료 후 제일 성능 좋은 ckt 를 저장하라는 인자
- Trainer 옵션 - compute_metrics 사전에 정의해둔 metrics function 을 입력해주는 인자 - callbacks Training 의 각 상태 별로 취해야 할 action 을 설정해주는 인자( 학습 조기종료 (Early Stopping) 옵션도 선택 가능) - patience : 학습이 개선되지 않는 상황을 얼마나 참을지 결정하는 횟수 - threshold : 학습이 개선되지 않음을 판단하는 임계점 - optimizers 학습최적화 알고리즘인 옵티마이저 (optimizer) 및 학습 스케줄러 (Learning Scheduler)지정해주는 인자
Inference - 학습된 모델의 체크포인트를 불러와 평가 데이터 (test data)에 대한 추론 (inference) 진행 - model.eval() 모델을 평가 모드로 전환하는 함수 - Batch normalization , Dropout 과 같은 레이어들이 학습 모드와 다르게 작동 - 학습을 하지 않는 추론이나 평가 시 사용 - torch.no_grad() 자동 미분 기능 비활성화하는 함수 - 모델 연산의 gradient를 저장하지 않음. 메모리 사용량을 줄이고 연산속도를 높일 수 있음
Evaluation - 모델의 예측값 (prediction)과 평가데이터 (test data)의 라벨 (label)값 사이에 평가 진행 - sklearn.metrics 내 accuracy, f1_score 등 활용