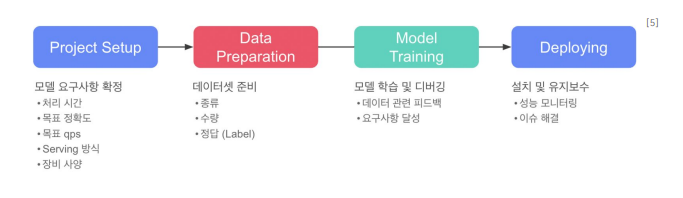
데이터 구축 프로세스데이터 구축 파이프라인데이터 수집 = 원시 데이터 수집 (Raw Data Collection)- 원시 데이터 수집 방법 : 직접 수집, 웹사이트로부터 크롤링, 오픈 소스 데이터 활용, 크라우드 소싱을 통한 데이터 수집- 데이터의 타당성 검토 - 저작권을 침해하는 데이터를 포함하고 있는지 여부 검토 - 개인정보를 포함하는 데이터를 포함하는지 여부 검토 - 윤리적인 문제가 발생할 수 있는 데이터인지 여부 검토 - 데이터 다양성 확보 획득하는 데이터가 일부 범주에만 치우치지 않고 가능한 다양한 시간, 공간, 집단 수준 등을 포함하도록 구성해야 함 - 데이터 편향 방지 및 윤리 준수 인공지능 모델이 사회적 윤리를 준수할 수 있도록 비윤리적 내용, 편견, 편향된 데이터의 수집..