첫 경진대회가 끝나고 바로 시작된 MLOps 프로젝트가 드디어 마무리되었습니다.
경진대회를 마친 후 약 일주일간 실시간 강의와 온라인 강의를 병행하며 MLOps의 기초를 배우고,
이를 활용한 프로젝트에 참여하게 되었습니다.
경진대회에서 매우 좋은 성과를 거둔 만큼, 프로젝트에서도 같은 팀원들과 함께 좋은 결과를 낼 수 있을 것이라 기대했습니다.
하지만 팀원 모두가 다소 지친 상태였고, 프로젝트 진행 중 예상치 못한 어려움이 많았습니다.
배운 내용을 바로 활용하기보다는 스스로 공부해야 할 부분이 많아 도전의 연속이었습니다.
그럼에도 불구하고, 훌륭한 팀원들의 도움과 협업 덕분에 프로젝트를 성공적으로 마무리할 수 있었습니다.
영화 추천 시스템 만들기
팀에서 정한 주제로 진행된 프로젝트는 흔히 접할 수 있는 아이디어일 수 있지만,
추천 시스템의 가장 기초가 되는 영화 추천 시스템을 만드는 일이었습니다.
프로젝트를 진행하면서 핵심은
1. 데이터 EDA와 분석
2. Streamlit으로 UI 구현
3. 백엔드로 연결하여 배포
데이터 EDA
- 데이터 EDA는 모두 함께 진행하였으며, 원래는 UI 팀으로 배정되었으나 여러 사정으로 인해 UI는 한 분이 전담하고, 백엔드는 또 다른 한 분이 담당하게 되었습니다. 이에 따라 저는 다른 팀원과 함께 데이터 분석을 진행하게 되었습니다.
- 데이터는 캐글에 있는 TMDB 영화 데이터셋과 사용자 데이터는 MovieLens 기반 데이터셋을 사용했습니다.
- 데이터 colume 확인
- 데이터 EDA에서 서로 feature들간의 상관관계가 높지 않은 점을 먼저 확인하였습니다.

- 그 외에도 각각 feature들의 분포를 확인하고, 그에 맞추어 고르게 되었습니다
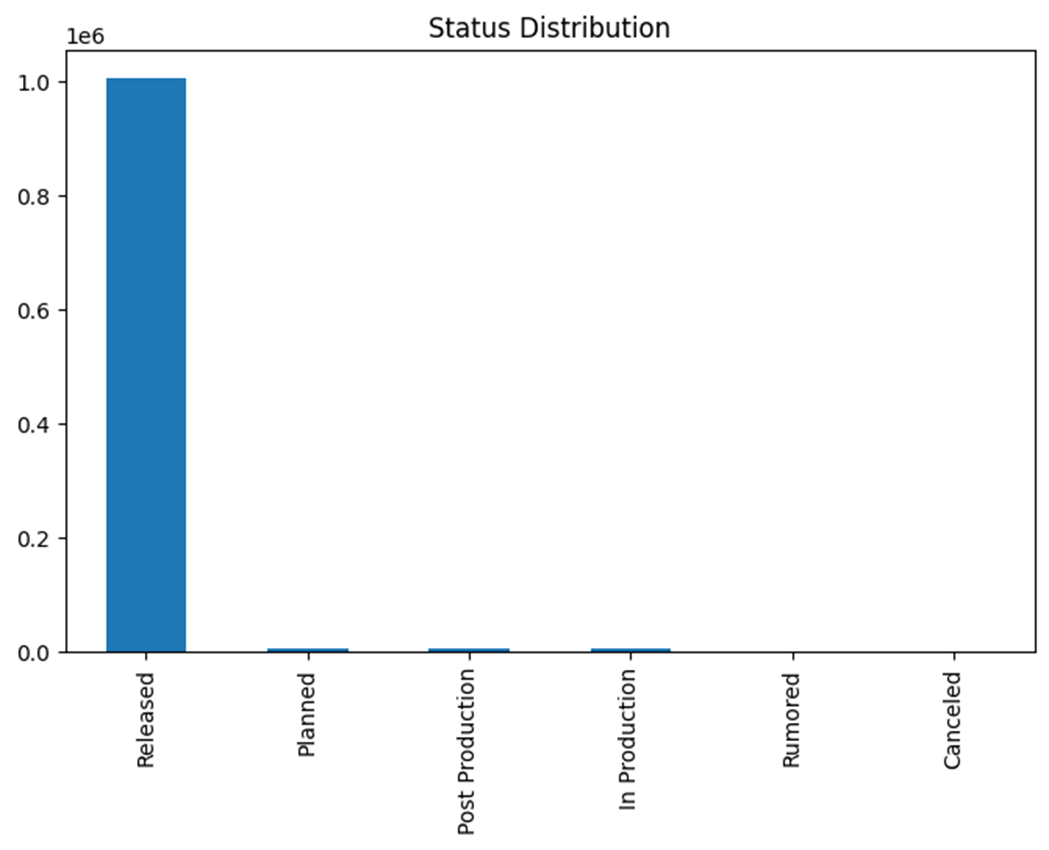

- 데이터 EDA를 통해서 colum을 확인하고, 그에 따라 어떤 데이터를 쓸 지, 어떻게 수정을 할지 골랐습니다.

데이터 전처리 및 필터링 과정은 다음과 같습니다. 초기 데이터 형태는 (1021773, 28) 이었으며,
결측치 처리를 위해 제목이 존재하는 경우만 남기고, 상태가 'Released'이며 개봉일이 있는 경우만 유지하였습니다.
TMDB 평점이 0이면 IMDB 평점으로 대체하였으며, 객체형 데이터가 null이면 "-"로 대체하였습니다.
또한, 러닝타임이 5분 미만인 데이터를 제거하고, 한국 및 영미권 영화만 선택하였습니다.
개봉일은 1980년 이후이면서 2024년 11월 25일 이전인 경우만 포함하였습니다.
이러한 과정을 거쳐 최종 사용 데이터 형태는 (223450, 19)로 정리되었습니다.
데이터 분석 및 처리
- 메타데이터 기반 추천 시스템
- 장르별 (Action, Adventure, Animation, Comedy, Crime, Documentary, Drama, Family, Fantasy, History, Horror, Music, Mystery, Romance, Science Fiction, TV Movie, Thriller, War, Western )
- 여러 개의 장르가 하나의 영화에 포함이 되는 경우가 많음-> 리스트화 시켜서 분석에 사용
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (각 100개씩 추천 후, UI에서는 7개를 랜덤으로 보여줌
- 시리즈별 영화 (20th Century Fox, Columbia Pictures, Metro-Goldwyn-Mayer, New Line Cinema, Orion Pictures, Paramount Pictures, Touchstone Pictures, Universal Pictures, Walt Disney, Warner Bros. Pictures)
- 회사 스크리닝 방법 : 수익이 높은 회사 10개, 영화 개수가 15개 초과인 회사만
- 필터링 : 투표수가 10 이상, 수익이 0이 아닌 경우
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (각 회사별 15개를 모아, 7개씩 랜덤으로 보여줌)
- (랜덤 추천) 전체 영화에서 랜덤으로 영화 추천
- 필터링 : 투표수가 500 이상, 폄점이 7점 이상, 1990년대 이후 개봉작
- (랜덤 추천) 한국 영화에서 랜덤으로 영화 추천
- 필터링 : 투표수가 10 이상, 폄점이 6점 이상, 1990년대 이후 개봉작
- (언어별 추천) 제작언어가 영어인 영화중에서 추천
- 필터링 : 투표수가 10 이상, 제작언어가 en
- 스크리닝 방법 : 투표수 > 평점 > 수익 > 최신 날짜 (100개를 모아, 7개씩 랜덤으로 보여줌)
- (언어별 추천) 제작언어가 한국어인 영화중에서 추천
- 필터링 : 투표수가 10 이상, 제작언어가 ko
- 스크리닝 방법 : 투표수 > 평점 > 수익 > 최신 날짜 (100개를 모아, 7개씩 랜덤으로 보여줌)
- (개봉일) 개봉일이 2024년 11월인 영화
- 필터링 : 평점이 있음, 투표수가 10 이상
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
- (개봉일) 개봉일이 2014년 11월인 영화
- 필터링 : 평점이 있음, 투표수가 10 이상
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
- (개봉일) 각 연대별(1990년 이전, 1990년대, 2000년대, 2010년대, 2020년대)
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (각 연도별로 30개를 모아, 7개씩 랜덤으로 보여줌)
- (러닝타임) 러닝타임이 50분 이상, 60분 이하의 영화
- 필터링 : 투표수가 100이상. 평점이 8이상
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
- (러닝타임) 러닝타임이 상위 3%안에 드는 영화 (149~201분)
- 필터링 : 투표수가 10이상
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
- 평점이 높은 영화
- 필터링 : 예산과 수익이 0이 아닌 경우, 투표수가 100이상
- 스크리닝 방법 : 평점 > 투표수 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
- 수익 / 예산 이 큰 영화
- 필터링 : 투표수가 10이상, 2000년대 이후 개봉
- 스크리닝 방법 : 수익 > 투표수 > 평점 > 최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
-> 이렇게 다양한 분류를 가지고, 이에 대해서 여러가지의 실험을 통해서 가장 적합하다고 생각하는 영화를 추천하게 되었습니다. 영화 추천에 있어서 기준은 어느정도는 우리가 아는 영화의 추천이 있어야 한다고 생각을 했습니다. 이 추천은 아무래도 메타데이터만을 다루는 것이니까, 이것을 확인을 해야한다고 생각했습니다.
처음엔 평점위주로 스크리닝을 했을 때, 예술영화 위주의 추천이 있었고, 거의 알지 못하는 영화가 추천이 되어서 이를 수정하고자 하다가 수익이 가장 우선으로 할 경우, 아는 영화가 많이 나오고 그 다음은 투표수라는 것을 알게 되었습니다. 결국 사람들이 가장 많이 보고 투표를 많이 한 영화들이 많이 알려진 영화라는 인사이트를 도출 하였습니다. - 협업 필터링 영화 추천 시스템
- 얻은 유저데이터를 바탕으로 진행을 하게 되었습니다.
- 유사 사용자 기반 : 사용자간의 cosine유사도를 계산하여 상위 10명의 추천의 영화
- 영화 평점 기반 : 사용자가 5점을 준 영화에 함께 5점을 준 사용자들을 추출(5점을 준 사용자가 3명인 경우의 다른 영화만 추천목록에 넣어줌) - 컨텐츠 기반 영화 추천 시스템
- 5점을 준 영화의 감독이 찍은 다른 영화
- 5점을 준 영화에 출연한 주요 배우가 찍은 다른 영화
- 5점을 준 영화가 개봉한 시기와 비슷하고, 장르가 같은 영화\
-> 아쉽게도 협업필터링과 컨텐츠 기반의 필터링은 제대로 이용이 되지 못했습니다.
프로젝트 결과물
영상을 첨부 하고 싶었는데ㅠㅠ20MB밖에 업로드가 안되어서 이렇게 사진으로 대체하게 되었습니다.
배포까지 완료를 했고, 직접 들어갈 수 있는 환경으로 구성이 되었으나 서버비의 문제로 주말중에 닫게 되었습니다.
프로젝트를 하면서 느낀점
프로젝트를 진행하며 많은 것을 느꼈습니다.
혼자서는 진행하기 어려웠을 프로젝트였고, 백엔드와 프론트엔드를 담당해 주신 팀원들께 정말 감사했습니다.
저는 주로 데이터를 다루었는데, 데이터를 다루는 일은 개인적으로 매우 좋아하는 분야라 즐겁게 작업할 수 있었습니다.
하지만 2주라는 짧은 프로젝트 기간은 다소 부담이 되어 밤샘 작업이 많았고, 제대로 잠을 자지 못하고 작업해야 하는 날도 많았습니다. 백엔드와 프론트엔드는 배우지 않고 바로 실전에 투입된 상황이라 '이게 맞나?'라는 생각이 자주 들었고, 프로젝트 기간이 한 달 정도로 더 길었더라면 좋았을 것 같다는 아쉬움이 남았습니다.
MLOps 프로젝트이지만 모든 내용을 충분히 배우지 못했다는 점이 아쉬웠습니다.
특히 Airflow나 Docker 사용법을 좀 더 깊이 익힐 수 있는 시간이 있었다면 더욱 좋았을 것입니다. 이러한 기술들을 배우지 못한 부분이 아쉽고, 백엔드를 좀 더 공부해야겠다는 필요성을 느꼈습니다.
비록 프로젝트 기간 내 배포는 하지 못했지만, 추가적으로 Streamlit을 활용해 개인적으로 프로젝트를 발전시켰습니다.
이 과정은 별도의 후기로 정리해 나중에 올릴 계획입니다.
팀원분들 덕분에 정말 잘 할 수 있었고, 좋은 팀원들을 만나서 자신이 생겼고, 다음 팀이 걱정이 조금 되긴 하지만, 이제 새로 시작하는 마음으로 마음을 다잡고 더 열심히 해보도록 하겠습니다.
'Upstage AI LAB 부트캠프 5기 > 성장 기록' 카테고리의 다른 글
| 컴퓨터 비전 첫 도전기: 경진대회에서 배운 것들 (1) | 2025.01.09 |
|---|---|
| DL 프로젝트 이론 탐구: 중반 학습 기록 (3) | 2024.12.17 |
| 처음 나선 경진대회, 도전과 성취의 여정 (3) | 2024.11.15 |
| Git 수업 후기: 협업과 관리의 필수 도구를 배우다 (5) | 2024.10.29 |
| 코딩 테스트의 첫걸음: 컴퓨터 공학을 처음 배우며 (3) | 2024.10.22 |