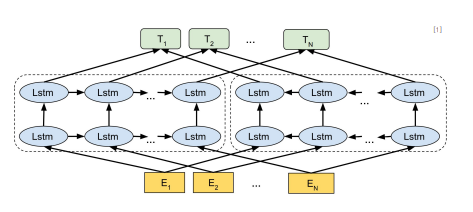
초기의 사전학습 언어 모델사전학습 (Pretrain)과 미세조정 (Fine-tuning) - 사전학습의 목표 - unlabeled text corpora로 부터 유용한 language representation을 배우는 것 - 사전학습 모델은 사전에 언어를 잘 이해했기 때문에, downstream task에 대해 라벨링된 데이터를 추가로 학습하여 좋은 성능을 얻을 수 있음 - E.g. 수능 국어(특정 downstream task)를 공부할 때, 글을 모르는 사람은(단순히 데이터로만 학습) 수능 국어에 능숙해 지는 데에 오랜 시간이 걸리고 (학습을 비교적 잘 하지못함), 사전에 글을 배운 사람 (사전학습 모델)은 비교적 수능 국어를 더 잘 익힘 (학습을 비교적 잘함)- 사전학습의 동기 ..