Convolution Layer - 네트워크가 비전 태스크를 수행하는 데에 유용한 Feature들을 학습할 수 있도록 함 - Filter(=Kernel): Input Image를 특정 크기의 Filter를 이용하여 탐색하면서 Convolution 연산을 시행하여 Filter 영역에 대한 특징을 추출 - Stride (S): Filter를 얼마만큼의 간격으로 움직이는 지를 나타냄 - Padding(P): Feature Map의 크기를 일정 수준으로 유지하기 위해서 임의의 값을 넣은 Pixel을 얼마나 추가했는지를 나타냄 - Zero Padding: 0으로 채운 Pixel을 주변에 채워 넣는 것
Activation Function - 네트워크에 비선형성을 가해주는 역할을 함 → Convolution 연산 결과 1차 함수를 얻게 되므로, Convolution Layer만으로는 선형적인 모델만 만들 수 있게 됨 → 따라서 Convolution 연산을 거친 뒤 비선형성을 지닌 함수(=Activation Function)를 통과시켜준다면, 복잡한 문제도 풀 수 있는 고차 함수 모델을 만들 수 있게 됨
구조 - Convolution - Pooling - Batch Normalization의 구조
- 8개의 레이어를 가짐
Convolution Layer
Activation Function - ReLU가 가장 좋은 성능을 보여 도입 !
Pooling Layer - Overlapping Pooling을 했을 때 그렇지 않은 경우 (F=2, S=2)보다 좋은 성능을 보였다고 함
Local Response Normalization (LRN) - Lateral Inhibition 현상: 강하게 활성화된 뉴런이 다른 뉴런의 값을 억제하는 현상 - 너무 강하게 활성화된 뉴런이 있을 경우 주변 뉴런들에 대해서 Normalization 진행 - Normalize를 통해 강하게 활성화된 뉴런의 값을 감소시켜, 특정 뉴런만 활성화되는 것을 막음 - 이후에는 Batch Normalization을 주로 사용
Overfitting 방지 - Overfitting : 학습 데이터에 너무 과적합(Overfitting)되어 학습되는 경우를 말함 - Overfitting된 모델의 경우 학습 데이터에 대해서는 좋은 성능을 나타내지만, 학습 데이터에서 본 적 없는 테스트 데이터에 대해서는 매우 낮은 성능을 보이게 됨 - 학습 데이터에서 보지 않은 데이터에 대해서 좋은 성능을 보이는 일반화(Generalization)가 잘 된 모델을 만드는 것이 궁극적인 목표이므로 Overfitting을 피하기 위한 방법들이 필요함
Data Augmentation - 학습 데이터에 변형(Augmentation)을 가해서 좀 더 다양성을 지닌 데이터로 학습될 수 있도록 하는 방법
Dropout - 뉴런 중 일부를 일정 비율(p)로 생략하면서 학습을 진행하는 방법 - 몇몇 뉴런의 값을 0으로 바꾸어서 학습 시에 영향을 미치지 못하도록 만들어 일정 뉴런의 값에 치중해 학습되는 것을 방지함 - Dropout은 학습 시에만 행해지고, 테스트를 할 때는 모든 뉴런을 사용함
VGGNet
Small Filters, Deeper Networks - 3x3 conv 세 개가 7x7 conv 하나와 비슷한 효과 (=effective receptive field) - 또한 더 적은 파라미터로 구현 가능함 - C가 레이어 당 채널 수일 때, 3 * (32C 2 ) vs 72C 2 - 하지만 더 많은 레이어를 쌓았을 때 non-linearities를 높일 수 있음
ResNet
구조
Efficiency of ResNet
Residual Connection - 깊은 네트워크일수록 Optimization이 어렵다 - Overfitting은 학습 데이터에서는 좋은 성능을 나타내지만, 테스트 데이터에서는 매우 낮은 성능을 보이는 것을 말함 - 그러므로 Training Error와 Test Error 모두 높은 Deep Plain Model의 경우 Overfitting으로 인한 현상이라고 보기 어려움 - 깊은 모델일수록 더 풍부한 Feature에 대해서 학습할 수 있다는 장점이 있음에도 불구하고 성능이 오르지 않은 것은 깊은 모델의 경우 Optimization이 더 어렵기 때문에 발생한 문제라고 해석할 수 있음
- Identity Mapping - 쌓여진 레이어가 그 다음 레이어에 바로 Optimize되는 것이 아니라 Residual Mapping에 Optimize되도록 만듦 - 추가적인 파라미터도 필요하지 않으며, Shortcut Connection만 추가되기 때문에 복잡한 곱셈 연산도 필요하지 않다는 장점을 지니고 있음 - 모델 F(x)는 F(x) = H(x) 가 되는 방향으로 optimize됨
Bottleneck Layer - 깊은 네트워크의 단점 - Convolution layer를 연속해서 쌓을 때 Feature Map의 Dimension(=Channel)을 커지거나 유지시키면서 다양한 특징에 대한 학습이 가능하도록 함 - Channel의 수가 늘어난다는 것은, Convolution 연산 시 필요한 Filter의 수가 많아진다는 것을 의미하기 때문 - 하지만 계속해서 Channel의 수가 늘어날 경우 모델이 깊어질수록 연산에 필요한 파라미터 수가 급격하게 늘어나기 때문에 학습에 어려움이 생기게 됨
- 1x1 Conv의 효과 - 3x3 Convolution Layer Input과 Output 간의 dimension을 맞추는 데에 사용됨 - Input과 Output간의 채널 수를 맞추면서도 모델의 파라미터 수는 크게 늘리지 않을 수 있게 됨
Batch Normalization - Input들이 잘 Normalize 되어 있지 않음 (Bias가 클 수 있다) - 특정 레이어에서 매우 큰 Weight를 가지게 될 수 있음 - 따라서 Input이 각 레이어마다 일정하게 scale 되어 계산될 수 있도록 하는 장치가 필요함 - Deep Network가 잘 학습될 수 있도록 함 - Gradient Flow를 개선시킴 - 더 빠르게 Converge될 수 있도록 함 - 학습 시 Regularization을 한 것 같은 효과를 얻을 수 있음 - 좀 더 Robust한 모델이 될 수 있도록 하는 데에 기여함 - ResNet에서는 모든 Convolution Layer 이후에 Batch Normalization을 해줌 (Conv - BN - ReLU 의 구조)
- 과정
- Input (x)의 shape = N x D - Learnable Scale and Shift Parameter (γ, β)의 shape = D - 즉 γ = σ, β = μ가 되도록 학습함
EfficientNet
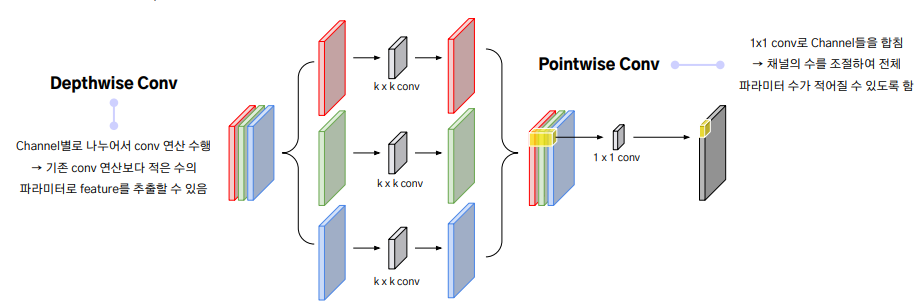
Baseline Model - MBConv Block = Mobile inverted Bottleneck Convolution (MBConv) - Depthwise Separable Convolution: Depthwise conv + Pointwise conv - Squeeze and Excitation: Feature를 압축했다가 증폭하는 과정을 통해 Feature의 중요도를 재조정 함
- Squeeze : Global Average Pooling 등을 사용하여 1x1xC 크기로 압축하는 과정 → 각 채널의 중요한 정보만 담고 있을 수 있도록 압축한 것 - Depthwise conv + Pointwise conv : 두 개의 FC layer를 더해주어 각 채널들의 중요도를 추출함 → 이를 기존 Feature Map에 곱해주게 되면, 채널의 중요도가 학습된 새로운 Feature Map을 얻을 수 있음
Baseline Model Scaling -> Baseline Model을 기반으로 다양하게 Scale up한 모델들 중 가장 효율적인 모델을 찾는다 ! - FLOPS vs. Accuracy Trade-off Curve - 깊은 모델의 필요성 : Resolution이 커지면, 더 큰 Receptive Field가 필요하므로 더 많은 Layer들을 쌓은 깊은 모델이 높은 정확도를 보임 - 더 넓은 Channel의 필요성 : 더 큰 Resolution를 사용하게 되면 이미지의 디테일들, 즉 High Frequency Information에 대한 정보도 포함되어 있다는 장점이 있는데, 이를 효과적으로 사용하기 위해서는 더 큰 Width를 가진 Channel이 필요함
Compound Scaling - Channel Width를 늘리기 - 모델의 Depth를 늘리기 - Input Image의 해상도 높이기
- Individual Scaling: 깊이, 넓이, 그리고 해상도를 각각 독립적으로 scaling하는 방법 - Compound Scaling: 깊이, 넓이, 그리고 해상도를 동시에 scaling하는 방법 - Compound Coefficient : uniformly scales network width, depth, and resolution in a principled way - 아래 식에서 상수이며, small grid search를 통해 결정됨 - 계산량은 깊이에 비례하고, 나머지 넓이와 해상도의 경우 그 제곱에 비례하므로 아래와 같은 비율로 결정
모델의 Hyperparameter를 업데이트 하는 방법 - 먼저 ϕ=1로 고정하고, α, β, γ에 대해서 small grid search 수행 - 그 결과, α=1.2, β=1.1, γ=1.15로 α⋅β2 ⋅γ2≈2 라는 결과를 얻음 - 다음으로 α, β, γ를 찾은 값으로 고정한 뒤, ϕ를 변화시키며 모델 전체의 크기를 scaling함
EfficientNet의 결과
CNN vs. 고전 컴퓨터 비전
고전 컴퓨터 비전 - 고전 컴퓨터 비전에서의 Filter - Sobel Filter: 정해진 Sobel Kernel을 통해 x 방향과 y 방향으로 변화율을 계산하여 엣지를 검출하게 되며, 학습 가능하지 않음.
현대의 컴퓨터 비전 - 학습 가능한 Filter의 등장 -고전 컴퓨터 비전의 방법만으로는 성능이 좋지 않거나 해결이 불가능했던 태스크들을 할 수 있게 됨 - CNN = Convolutional Neural Network - Convolution Filter: 현대에 들어서는 Convolution 연산을 통해 산출한 결과를 정답지(Ground Truth, GT)와 비교하여 오차를 줄여나가는 방식 등으로 계속 업데이트 되는 학습 가능한 필터를 많이 사용하게 됨.
학습 가능한 파라미터 - 학습 가능한 파라미터들을 가진 레이어 예시 - Convolution Layer - Batch Normalization Layer - Fully Connected Layer
- 학습 가능하지 않은 레이어 예시 - Activation Layer - Pooling Layer
CNN Layer
CNN 모델의 구성 - Convolution Block: Convolution Layer → Batch normalization Layer → Activation Layer - Pooling Layer
Convolution Layer - 네트워크가 비전 태스크를 수행하는 데에 유용한 Feature들을 학습할 수 있도록 함 - Convolution Layer를 여러개 쌓는 경우, 뒤 레이어의 결괏값 하나를 만드는데 사용되는 이미지의 범위가 넓어진다 - Convolution Layer의 초반 Layer의 경우 edge와 같은 low-level feature를 주로 학습하게 되고, 후반 Layer의 경우 shape과 같은 high-level feature를 주로 학습하게 됨
Batch Normalization - Deep network가 잘 학습될 수 있도록 함 - Gradient flow를 개선시킴 - 더 빠르게 converge될 수 있도록 함 - 학습 시 regularization을 한 것 같은 효과를 얻을 수 있음 - 좀 더 robust한 모델이 될 수 있도록 하는 데에 기여함 (즉, overfitting을 방지하는 데에 도움을 줌) - 보통 Convolution Layer 다음, 그리고 Activation Layer 전에 Batch Normalization을 해줌
Activation Layer - 모델에 비선형성을 부여해 주기 위해서 사용됨 - 선형 함수의 Layer들로만 구성될 경우 여러 개를 쌓더라도 선형 함수 하나로 표현될 수 있는 모델이 될 뿐이기 때문에, 깊은 네트워크의 장점을 살릴 수 없게 됨
- Sigmoid : [0, 1] 사이의 값으로 변경해 줌 - Gradient 값이 kill 되는 현상이 생길 수 있음 (e.g. σ(x)의 값이 0에 가깝거나 1에 가까운 값일 경우) - Sigmoid를 거친 결과는 0에 centroid되어 있지 않음 (항상 양수 값만 가짐) - Exponential 함수를 계산해야 하므로 cost가 높음
- Tanh : [-1, 1] 사이의 값으로 변경해 줌 - 여전히 gradient 값이 kill 되는 현상이 생길 수 있음 - Tanh를 거친 결과는 0에 centroid되어 있음
- ReLU : 음수면 0, 양수면 입력 그대로 - 양수의 값을 가질 경우 gradient가 kill되지 않음 - Computational cost가 매우 적음 - Sigmoid나 tanh 함수보다 매우 빠르게 수렴함 (e.g. 대략 6배 빠름) - ReLU를 거친 결과는 zero-centroid가 아님 - 음수값을 가질 경우 gradient가 0이므로 update 되지 않음
- Leaky ReLU : 음수면 입력의 1/10, 양수면 입력 그대로 - 양수의 값을 가질 경우 gradient가 kill되지 않음 - Computational cost가 매우 적음 - Sigmoid나 tanh 함수보다 매우 빠르게 수렴함 (e.g. 대략 6배 빠름) - ReLU를 거친 결과는 zero-centroid가 아님 - 음수값을 가질 경우 gradient가 0이므로 update 되지 않음
Pooling Layer - Feature Map에 Spatial Aggregation을 시켜줌 - 모델의 파라미터 수를 줄여줌 - 더 넓은 Receptive Field를 볼 수 있게 해줌
- Max Pooling vs. Average Pooling - Max Pooling의 단점: 정보의 손실이 일어날 수 있음 - Average Pooling의 단점: 중요한 정보가 희석될 수 있음
CAM (Class Activation Mapping)
Fully Connected Layer (FC Layer)의 단점: Flatten하는 과정을 거치기 때문에 Pixel의 위치 정보를 잃게 됨
Global Average Pooling: Flatten하는 대신 Global Average Pooling을 거친 것으로, Feature Map 하나 당 하나의 특징 변수(Fk)로 변환하게 됨.
구조 - FC layer 대신 GAP을 수행하여 각 클래스로 분류될 확률에 영향을 미친 객체의 좌표 (x,y)를 추출할 수 있음
결과 -Global Average Pooling (GAP): 각 Feature Map에서 전체적인 특징들을 찾아내게 되어 Localization 능력이 좋음 -Global Max Pooling (GMP): 각 Feature Map 에서 가장 값이 큰 값을 추출하는 방법으로, Feature Map에서 뚜렷한 특징들만 찾아내게 되어 Localization 능력이 GAP보다는 낮다고 함