Object Detection = Localization + Classification - 두 가지의 task를 분리하여 2 stage로 따로 수행 - Stage 1: 이미지 내에서 object가 있다고 판단되는 위치 찾기 (Region proposal) - Stage 2: 각 위치에 있는 object의 종류 판단 (Classification)
R-CNN
- 2-stage detector의 최초 모델 - Region proposals + CNN
- Sliding Window - 고정된 크기의 window를 이미지 내에서 sliding하면서 객체의 위치를 찾아내는 방법 -계산 비용이 높고 속도가 매우 느림 -고정된 크기의 window
- Selective Search - 초기에 매우 작은 픽셀 단위의 region을 잡고, 유사성이 높은 region들을 점차적으로 병합해나가는 방법 - 색상, 질감, 경계 등을 기준으로 유사성이 높은 region을 병합 - Sliding window의 두 가지 단점 해결
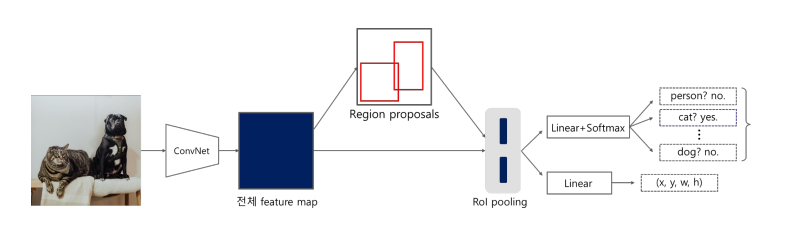
R-CNN 동작 과정 1. Input image에서 selective search를 통해 약 2000개의 RoI(Region of Interest) 생성 2. 각 RoI 영역을 모두 동일한 크기로 warping : 이후에 통과할 CNN의 마지막 fc layer의 input size가 고정되어 있기 때문 3. 조정된 RoI를 각각 CNN에 넣어서 feature 추출 (2000x4096) - Region마다 4096-d의 feature vector로 추출 - Pretrained AlexNet 사용 4-1. 추출된 feature vector를 SVM에 넣어서 각 RoI의 object에 대한 classification (2000x(C+1)) - C+1: class 개수(C) + background(1) 4-2. 추출된 feature vector를 regression을 통해 각 RoI의 bounding box 위치 조정 - Selective search의 부정확한 bounding box 위치 조정
R-CNN의 단점 - 약 2000개의 RoI 각각에 대해 CNN 연산 → 연산량이 많고 속도가 매우 느림 - 모든 RoI를 동일한 사이즈로 맞추기 위해 이미지를 crop/resize하는 과정 필요 → 성능 저하 - Stage2의 모델(CNN, SVM, bbox reg) 모두 따로 학습
Fast R-CNN
- 단일 CNN을 통해 연산량 감소 - RoI projection 모듈을 통해 CNN 연산을 줄이고 속도를 개선한 모델 - RoI pooling 모듈을 통해 이미지 사이즈 강제 조정하는 과정 제거
- RoI Projection - RoI Projection의 등장 배경 : R-CNN에서는 2000개의 RoI를 뽑고, 이후 CNN에 통과 (2000번의 CNN 연산) → CNN을 한번만 통과하여, feature vector를 얻을 수 있을까? → Feature map을 한번만 추출하고, 그 위에서 RoI 위치에 맞는 feature vector를 추출하자! → CNN 연산 2000번 → 1번
- 사이즈가 변한 feature map에 RoI를 투영하는 과정 - CNN 연산 이후, feature map의 사이즈가 변할 수 있음
- RoI Pooling : 어떤 크기의 feature map이 들어와도 동일한 사이즈로 pooling하고자 하는 방법 - RoI를 지정된 size(WxH)에 맞추기 위해 그리드 설정 (6*6→2*2 / 4*6→2*2) - 설정된 각 그리드에서 max 값을 가져와서 최종적으로 같은 size로 통일
- RoI Pooling의 등장 배경 : CNN을 먼저 통과하기 때문에 RoI를 crop/resize하는 과정 없음 - Fc layer의 input으로 들어가기 전에 feature vector 크기를 조정해야 함
- Fast R-CNN 동작 과정 1-1. Input image에서 selective search를 통해 약 2000개의 roi 생성 1-2. 단일 CNN 연산으로 전체 feature map 생성 2. RoI projection, RoI pooling으로 각 RoI에 맞는 고정된 사이즈의 feature vector 생성 3. 추출된 feature vector에 대해 linear, softmax 연산 수행 - 이후, 각 RoI의 object에 대한 classification과 Bounding box regression 수행
R-CNN, Fast R-CNN의 단점 - 픽셀 단위부터 영역을 병합하는 selective search는 GPU와 CPU 연산이 모두 필요하며 매우 느림 - GPU에서만 연산하는 network와 분리되어 end-to-end 학습이 불가
Faster R-CNN
- Selective search를 제거하고 Region Proposal Network(RPN) 모듈을 사용하여 연산을 더 가속화한 모델 - 전체 프레임워크가 한번에 연산되는 end-to-end 모델
- Region Proposal Network (RPN) 이란? GPU에서만 연산하여 RoI를 찾는 network를 만들자! - 미리 지정된 크기의 anchor box를 이용하여 roi search
- Region Proposal Network (RPN) 동작 과정 1. CNN을 통해 얻은 feature map을 input으로 받아서 intermediate layer 생성 - 3*3*256 또는 3*3*512 convolution 사용 2. Intermediate layer의 feature map을 입력받아 classification - 1*1*18 convolution: 2(object 여부) x 9(anchor의 개수) 3. Intermediate layer의 feature map을 입력받아 bounding box regression - 1*1*36 convolution: 4(bbox의 좌표) * 9(anchor 개수)
- Non-maximum Suppression (NMS) - RPN으로 생성된 RoI 중에서 유사한 bounding box들을 제거하기 위해 사용 1. 각 class에 대한 confidence score를 기준으로 내림차순 정렬 2. Score가 가장 높은 box를 기준으로 IoU (Intersection of Union) 계산 3. IoU가 지정된 threshold 이상인 box들 제거 - 겹치는 영역이 클수록 같은 물체를 검출하고 있다고 판단 4. Bbox list가 빌 때까지 내림차순으로 IoU 계산/제거 과정 반복
Faster R-CNN 동작 과정 1. CNN을 통해 전체 feature map 추출 2. 생성된 feature map을 RPN, NMS 연산 후 RoI 생성 3. RoI projection, RoI pooling을 통해 모든 RoI를 동일한 사이즈로 변환 4. Softmax + bounding box regression 동시에 수행 (multi-task 학습)
1-Stage Detector
- 두 단계를 합쳐 속도가 더 빠르고 효율적인, 실시간 탐지에 적합한 모델
YOLO v1
- Classification과 localization을 동시에 포함하는 loss로 학습하는 end-to-end 모델
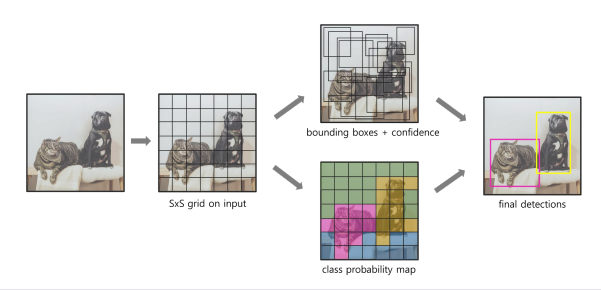
-Region proposal 단계를 제거하고, bounding box와 class를 동시에 예측 -전체 이미지를 한번에 보고 추론하기 때문에 맥락적 이해 증가
동작 과정 1. Input image를 SxS 크기의 grid cell로 분할 -객체의 중심이 특정 grid cell에 위치할 경우, 해당 grid cell이 그 object의 탐지를 담당하도록 할당 (assign) 2. 각 grid cell에서 B개의 bounding box와, 해당 bbox에 대한 confidence score 계산 3. 각 grid cell에서, 해당 cell에 객체가 존재한다고 가정했을 때 특정 class일 조건부 확률 계산 4. 각 bbox에 대한 class별 confidence score 계산을 통해 최종 예측
-Darknet :GoogleNet을 변형하여 만든 YOLO v1의 독자적인 네트워크 (ImageNet-pretrained) -24개의 convolution layer: feature map 추출 -2개의 fully connected layer: 각각 box, class 예측 담당 -Darknet Output 후처리 -이미지에서 예측된 모든 bounding boxes들의 집합 -지정된 threshold를 기준으로, confidence score가 threshold 이하일 경우 해당 box 제거(score 0으로 설정) -confidence score를 기준으로 box 내림차순 정렬 -NMS를 통해 불필요한 box 제거(score 0으로 설정) (score가 0이 아닌 남은 bboxes의 집합이 최종 prediction)
Loss Function -세 가지 loss의 sum of squared error(SSE)로 total loss function 구성 1. Localization loss 2. Confidence loss 3. Classification loss
한계점
- Fast R-CNN과 비교했을 때 높은 localization 에러율
- Region proposal-based 방법들에 비해 낮은 recall ⇒ YOLO만큼 빠르면서도 더 정확한 모델 필요
YOLO v2 - YOLO 9000: Better, Faster, Stronger - Better: 정확도(mAP) 향상 1. Batch normalization - 기존 YOLO v1 모델에서 모든 convolution layer에 batch normalization을 사용하고 dropout 제거 2. High resolution classifier - YOLO v1에서는 224*224 기준으로 pretrained된 network를 사용하면서 448*448의 input 이미지를 사용하여 해상도 불일치 문제가 있었음 - YOLO v2에서는 network를 448*448 image에 다시 fine-tuning하여 사용 3. Convolutional with anchor boxes - YOLO v1은 anchor box가 없으며, bbox의 좌표를 랜덤값으로부터 직접 예측 - YOLO v2에서는 fc layer를 모두 제거하고 anchor box 도입 - 좌표값 x,y,w,h를 직접 예측하는 것보다 상대적 offset을 보정하는 것이 쉽기 때문 4. Dimension clusters - Anchor box의 개수를 미리 지정하는 대신 최적의 개수를 학습하여 찾음 - K-means clustering를 사용해서, 5개의 anchor box를 사용했을 때 가장 좋은 성능을 보임 5. Direct location prediction - YOLO 모델에 anchor box를 도입할 경우, 학습 초기 단계에 모델이 불안정함 - 좌표의 학습 계수인 와 에 제한된 범위가 없어서 x, y값이 무한할 수 있기 때문 - Grid cell에 상대적인 위치 좌표를 예측하는 방법 사용 6. Fine-grained features - 크기가 작은 feature map은 low-level 정보 부족함 - 이전 convolution layer의 output을 분할하여 연결한 vector를 가져오는 방식 사용 7. Multi-scale training - 다양한 input 이미지를 학습하여 모델의 robustness 증가 - 10 batch마다 input 이미지의 크기를 랜덤하게 선택 - 모델이 32배로 downsample하도록 설계되어 있기 때문에, 32배수인 {320, 352, … , 608} 중에서 선택
- Faster: 속도(fps) 향상 - Darknet-19라는 독자적인 네트워크를 사용하여 YOLOv1보다 parameter 수를 줄이고 속도 향상 - 마지막 fc layer를 제거하고 global average pooling 사용 - 1*1 convolution layer 추가
- Stronger: 더 많은 class에 대한 학습/예측 - Classification의 데이터셋(ImageNet)과 detection의 데이터셋(COCO)를 함께 사용 → class 개수 9000개 - ImageNet의 label들은 영어 단어의 의미적 관계를 연결하는 WordNet에서 가져온 것 - 그래프로 표현된 WordNet으로부터 계층 트리(hierarchical tree)인 WordTree 구축 - “물리적 객체”(“physical object”)라는 class를 root node로 두고 그 하위 범주들을 자식 노드로 뻗어나가서 계층 구성 - WordTree 구성 이후 각 node의 확률을 예측할 때는 조건부 확률 사용 : Root node인 physical object까지 따라 올라가며 확률곱 - (ImageNet 데이터셋 : COCO 데이터셋 = 4 : 1) 비율 조정 - WordTree를 사용하여 classification과 detection dataset을 함께 학습하는 joint training
YOLO v3 - Multi-scale feature maps 사용을 통해 다양한 크기의 객체를 더 잘 탐지하도록 모델 개선 - 더 빠른 속도와 정확도를 달성하는 Darknet-53 backbone 사용 - 세 개의 feature map scale을 사용하여 객체 탐지 수행 - Feature pyramid network 사용
- Darknet-53 - Residual connection 적용 - 총 53개의 Convolution layer - Darknet-19보다 나은 성능이지만 여전히 ResNet-101, ResNet-152보다 빠른 속도
YOLO v4 - 당시의 최신 딥러닝 기법들을 활용하여 정확도와 속도 향상 - Bag of Freebies, Bag of Specials (에 포함되는 8가지 기법 사용) - CSPDarknet-53 backbone 사용 - Inference cost를 증가시키지 않고 training cost만 추가하여 정확도를 향상시키는 기법 (CutMix and Mosaic data augmentation, Dropblock regularization, Class label smoothing) - Inference cost를 조금 증가시키지만 정확도를 크게 향상시키는 기법 (Mish activation, Cross-stage partial connections (CSP), Multi-input weighted residual connections (MiWRC))
- CSPDarknet-53 - CSPNet과 YOLOv3의 DarkNet-53 구조를 결합한 네트워크 - parameter 수가 많음에도 속도가 빠르고, 작지 않은 receptive field를 가짐 - CSPNet (Cross Stage Hierarchical Networks): 네트워크 중간에서 feature map을 두 부분으로 분할 이후 하나의 feature map에 대한 연산 후에 다시 결합하는 방법 - 정확도는 유지하면서 연산량 줄이기, 연산 bottleneck 제거, 메모리 cost 감소
Neck
- 등장 배경 : 기존의 detector 모델들은 일반적으로 하나의 고정된 해상도의 feature map 사용 → 다양한 크기의 객체를 동시에 처리하는 것은 어려움
Neck -다양한 크기의 물체를 더 잘 탐지하기 위해 보완된 구조 - 다양한 객체를 더 잘 탐지할 수 있음 - 예시 :FPN, PANet, DetectoRS, BiFPN, NasFPN, AugFPN
- CNN의 여러 layer에서 추출되는 feature map은 객체의 다양한 크기와 모양을 탐지하는데 적합 - CNN을 거치면서 feature map의 spatial resolution은 줄어들기 때문에 - Early layers: 작은 객체나 low-level feature 탐지에 더 적합 - Later layers: 큰 객체나 high-level feature 탐지에 더 적합
FPN
기존방법 Featurized Image Pyramid - 이미지를 여러 scale로 변환하여 feature map을 생성하고, 네트워크에 입력하는 방법 - 다양한 scale의 객체를 탐지하는 성능 ↑ 각 이미지를 독립적으로 처리하기 때문에 속도 ↓
Single Feature Map - 단일 scale의 이미지만 사용하여 feature map을 생성하고, 단일 feature map으로 예측하는 방법 - 다양한 scale의 객체를 탐지하는 성능 ↓ 단일 이미지만 사용하기 때문에 속도 ↑
Pyramidal Feature Hierarchy - 단일 이미지만 사용하고, CNN에서 지정된 layer마다 feature map을 추출하여 예측하는 방법 - feature map을 독립적으로 사용하여 다른 해상도에서 얻은 semantic을 활용하지 못함
Feature Pyramid Network (FPN) - 지정된 layer의 feature map을 사용하며, 상위 level의 semantic을 함께 활용하는 방법 - Bottom-up pathway: CNN에서 이미지를 forward-pass하며 해상도가 작아지는 feature map을 추출하는 과정 - Top-down pathway: Lateral connection을 통해 각 layer에서 나온 feature map을 하위 layer의 feature map 해상도와 동일하게 맞추는 과정
- Lateral connection - Nearest neighbor upsampling을 통해 상위 layer의 feature map 해상도를 2배로 키움 - 1*1 convolution을 통해 하위 layer의 feature map channel을 조정하고 두개의 map을 결합
동작 과정 1. {C2, C3, C4, C5}: Bottom-up pathway를 통해, 해상도가 2배씩 작아지는 feature map 추출 - Backbone CNN으로는 ResNet 사용 2. {M2, M3, M4, M5}: Top-down pathway와 lateral connection을 통해 상위 level부터 feature map의 semantic 전달하여 결합 3. {P2, P3, P4, P5}: 결합된 feature map에 3*3 convolution을 수행하여 최종 feature map 생성 4. 최종 feature map에서 classification, bounding box regression을 수행한 후에 가장 확률이 높은 top-N개의 bounding box 선택
한계점 - Low-level에 가까운 feature일수록 output까지 semantic이 잘 전달되지 않음 - Top-down의 단방향 feature 통합은 semantic 교환이 충분히 이루어지지 않음 - 고정된 architecture 또는 고정된 layers, receptive fields를 가질 경우 context 정보가 충분하지 않을 수 있음
FPN 이후 - PANet (Path Aggregation Network for Instance Segmentation) : Bottom-up path를 한번 더 추가하고, low-level과 high-level semantic이 더 잘 통합되도록 설계 - BiFPN (Bi-directional Feature Pyramid) : Feature를 양방향으로 통합하여 더 많은 정보 교환이 이루어질 수 있도록 설계 - NAS-FPN (Neural Architecture Search-FPN) : 더 다양한 scale의 feature를 보고, 효율적이고 성능이 좋은 FPN architecture를 자동으로 찾을 수 있도록 설계 - AugFPN (Augmented Feature Pyramid Network) : Pyramid layers에 추가적인 convolution 연산을 추가하여 더 많은 -context를 볼 수 있도록 설계 - A2-FPN, GraphFPN 등… Neck 구조의 성능을 향상시키는 여러 모델 발전
Transformer-based Detector
Transformer-based Detector - 여러 task에서 뛰어난 성능을 보이는 Transformer 구조를 활용함으로써, 더 간결한 구조로 높은 성능을 보임 - Anchor boxes, RPN, NMS와 같은 hand-crafted 과정 제거
Why DETR (DEtection TRansformer)? - Object detection이란 image에서 object의 bounding box와 class를 같이 예측하는 set prediction - 기존의 object detection algorithm (Yolo, Faster-RCNN 등)은 indirect set prediction - 또한 기존의 모델들은 사람이 미리 정의한 prior knowledge를 사용 - NMS, anchor box 등 사람이 정의한 post processing algorithm - 즉, 사람의 bias가 모델 성능에 많은 영향을 끼침 - DETR에서는 direct set prediction으로 object detection task에 접근 - Direct set prediction으로 object detection task를 풀기 위해서는? - Architecture for direct set prediction -Direct set prediction loss
Overview 1. Backbone(feature extractor) + positional encoding - Transformer encoder로 들어갈 input processing 2. Encoder - Transformer encoder 구조를 활용하여, image feature에 대한 전역적인 context 생성 3. Decoder - 인코딩된 feature를 기반으로 N개의 query에 맞는 object 예측 4. Prediction heads - Decoder의 output을 보정 - Query에 순서가 없기 때문에 예측 bbox와 gt bbox를 맞춰주는 set-prediction 수행
- Positional Encoding - Vanilla transformer의 positional encoding을 2D로 일반화하여 적용 - Sin과 cos 각각 독립적으로 2/d만큼 생성한 후 concat - 동일하게 d*hw 크기의 vector(positional embedding)가 생성
- Positional Encoding - Vanilla transformer의 positional encoding을 2D로 일반화하여 적용 - Sin과 cos 각각 독립적으로 2/d만큼 생성한 후 concat - 동일하게 d*hw 크기의 vector(positional embedding)가 생성
- Encoder - Input 형태에 맞게 변환된 feature vector d*hw와 positional embedding d*hw을 더하여 encoder에 입력 - Positional encoding은 key와 query에만 적용 - Attention mechanism을 통해 feature map의 모든 pixel 사이의 관계를 학습 - Locality 특성을 가지는 CNN과 달리 전역적인 정보를 보며, 이미지 내 object의 위치, 관계 등을 함께 학습 - FFN을 통한 추가적인 선형 연산과 normalization 등을 통해 학습 보조 - 최종적으로 전체 이미지의 맥락을 학습한 output embedding d*hw 생성
- Object Query - DETR은 사전에 지정된 N개의 object만 탐지하는 모델 - 이미지 내 object의 정보를 담기 위한 slot인 object query 활용 - Zero initialized된 query vector(N*d) 생성
-Decoder -첫 번째 self-attention을 통해 N개의 query간의 관계 학습 - 해당 layer는 큰 성능 차이 없이 제거 가능 - Encoder의 output vector와 object queries 입력 - 이미지 내의 전역적인 정보를 담고 있는 encoder의 결과물과 attention을 함으로써, N개의 query가 어떤 위치에서 object를 찾을 수 있는지 학습 - 추가적인 선형 연산과 normalization 등을 통해 학습 보조 - 최종적으로 N개의 query에 대한 예측 정보를 담고 있는 output embedding d*hw 생성 1. Encoder-decoder attention: N개의 query를 배치할, object가 있을 확률이 높은 위치 탐지 2. Self-attention: N개의 query가 같은 object를 탐지하지 않고 일대일 매칭을 잘 수행할 수 있도록 분배
- Classification Head - Decoder의 output 입력 - FFN을 통해 각 N개에 대한 class probability 계산 - class개수(C) + background(1) - FFN을 통해 bounding box 계산
- Bipartite Matching - Decoder에서 object query는 parallel하게 생성됐기 때문에, output 예측에 object 순서가 없는 상태 - N개의 예측이 이미지 내의 어떤 object를 탐지하는지 1:1로 매칭해주는 set prediction 필요 - Prediction bbox와 gt bbox의 perfect bipartite matching problem - 이를 1:1 매칭했을 때, 가장 loss가 작은 조합이 올바른 매칭일 것이라고 가정 - N*N개의 모든 조합을 고려하면 계산적, 시간적으로 비효율적이기 때문에 hungarian algorithm을 이용하여 최적 탐색
- Hungarian Algorithm - Source 집합 I와 target 집합 J가 있을 때, i∈I, j∈J인 원소들에 대해 i→j의 매칭 비용을 c(i,j)라고 한다면 - 모든 일대일대응 σ: i→j 중에서 가장 c가 작은 조합을 찾는 것 1. Source 집합 I(prediction bboxes)와 target 집합 J(gt bboxes)를 행렬로 표현 2. 각 bbox 조합에 대한 cost를 연산하여 행렬값 채우기 → Matching cost에는 classification loss와 bbox loss를 함께 사용 2-1. Classification loss: class probability 사용 2-2. bbox loss: l1-loss Anchor와 같은 어떠한 가정 없이 bbox가 예측되기 때문에 bbox loss가 매우 큼 - 절대적인 거리를 측정하는 l1-loss만 사용하면 bbox 사이즈에 따른 상대적인 loss 차이가 큼 - bbox의 크기가 크면 좌표값의 차이도 크고 bbox의 크기가 작으면 좌표값의 차이도 작음 2-2. bbox loss: l1 loss + Generalized IoU (GIoU)를 함께 사용하여 해결 - GIoU는 bounding box의 scale에 의존적이지 않은 loss - Pred bbox와 gt bbox를 동시에 포괄하는 새로운 box C 생성 2-3. Matching cost = classification loss와 bbox loss의 합 3. Hungarian algorithm을 통해 최적의 일대일 조합 찾기 : Matching cost를 최소화하는 최적의 조합 3-1. 첫 번째 행(row)에서 최솟값을 구한 후, 모든 원소에서 빼주기 3-2. 모든 행에 대해 동일한 연산 수행 3-3. 모든 열(column)에 대해 동일한 연산 수행 : 최소값이 0일 경우 해당 열의 연산 생략 3-4. 모든 0을 커버(cover)할 수 있는 행 또는 열을 최소 개수로 search - 찾은 행 또는 열의 최소 개수가 원소의 개수(n=4)와 같거나 클 경우, 바로 최적의 매칭 찾기 - 현재의 경우처럼 원소의 개수보다 작을 경우, 이어서 연산 수행 3-5. 찾은 행 또는 열을 제외한 나머지 원소 중에서 최소값을 구한 후, 해당되지 않는 모든 행의 원소에서 빼주기 3-6. 음수가 포함된 열에서, 최소값의 절댓값 더해주기 3-7. cover하는 행과 열의 수가 아직 같은 조건이므로 동일한 연산 한번 더 수행 3-8. cover하는 행과 열의 개수가 n보다 크거나 같기 때문에 연산 종료 3-9. 최적의 매칭 찾기 4. 매칭된 최적의 조합을 기반으로 최종 loss function인 hungarian loss 계산 - classification loss로 negative log likelihood 사용
DETR with Huggingface - ResNet50 backbone을 가지는 huggingface의 pretrained-DETR 불러오고 사용해보기 - DetrImageProcessor: 이미지는 모델에 입력하기 전에 전처리를 수행하는 프로세서 - DetrForObjectDetection: DETR 모델이 구현되어 있는 클래스 - 프로세서를 통해 입력 이미지를 전처리한 후 모델에 inference - post_process_object_detection 함수를 사용하여 모델 output 후처리