규칙기반 및 통계기반 자연언어처리
- 규칙 기반 NLP
- Rule에 맞게 처리하는 시스템
- Rule 생성을 위해서는 Task에 대한 전문 지식 필요
- 데이터를 살펴보면, 누가봐도 전문가가 만들었어야 하는 시대
- 형태소 분석, 구문 분석, 의미 분석 등
- NLP에서의 Task 지식 == 언어학적 지식
- 적은 양의 데이터로 일반화 가능
- 결론 도출의 논리적 추론 가능
- 학습에 필요한 데이터가 비교적 적게 필요
- 이를 제작한 전문가의 실력을 넘어서기 매우 어려움
- 해당 전문가의 오류를 동일하게 반복
- 규칙 구축에 많은 시간과 비용 소요
- Toy task에 주로 적용되었음 - 통계기반 NLP
- 대량의 텍스트 데이터로 통계를 내어 단어를 표현
- “모두 (군중, 여러분)”가 “무의식적”으로 생산한 대량의 데이터(=빅데이터)를 활용
통계 기반 방법론
- 특정 단어에 주목했을 때, 그 주변에서 어떤 단어가 몇 번이나 등장하는지 카운트
- 사람의 지식으로 가득한 말뭉치에서 자동으로, 효율적으로 핵심을 추출하기 위한 목적 => 의미를 3차원의 벡터로 표현: 단어의 분산표현
통계적 언어모델 (SLM)
- 이전 단어들로 부터 다음 단어에 대한 확률을 구함 (확률기반)
- 코퍼스에 등장하지 않은 단어 시퀀스에 대해서는 확률 측정이 불가 ⇒ 예측 불가
- Sparsity Problem으로 인한 한계 도달
- Sparsity Problem : 충분한 양의 데이터를 사용하지 못하여 언어를 정확하게 modeling하지 못하는 문제점 - 통계 기반 NLP vs 규칙 기반 NLP
- 전문가의 중요성 감소
- 더 많은 데이터가 필요
- 개발이 쉽고 빠름
기계학습 및 딥러닝기반 자연언어처리 ( ML & DL in NLP)
- “전문가” + “모두 (군중, 여러분)” 공존의 시대
- 머신러닝/딥러닝 기반 모델
- 학습에 사용할 데이터의 질이 좋고 양이 많으면 인간의 실력을 넘어설 수 있음
- 인간이 생각하지 못한 새로운 방법을 사용할 수 있음 (예: 이세돌과 알파고의 대결에서 37수, 78수)
- Data hungry
- 결과에 대한 해석의 어려움
- 논리적 추론이 아닌 귀납적 근사에 의한 결론 생성
- Neural Machine Translation
- 지도학습을 위한 데이터
- 정답(레이블)을 필요로하는 데이터
- 시간 및 금전적 비용 발생
- 대량으로 구축하기 어려움
- 대부분의 딥러닝 시스템 구축에는 지도학습과정이 수반되어야 하므로, 이를 위한 데이터 확보 방법에 대한 계획을 세우는 것이 중요
- 비지도학습을 위한 데이터
- 정답(레이블)이 필요하지 않은 데이터 (ex.입력과 출력이 동일한 Auto-Encoder 학습 방법)
- 손쉽게 대량으로 구축할 수 있음
- 일부 예외적인 경우를 제외하고는 실제 사용 가능한 수준의 성능을 낼 수 있음
- 지도학습을 보완하여 성능을 더욱 향상시키는 방법으로 사용됨 (ex. BERT, GPT3와 같은 Pretrain 언어모델) - Supervised Learning Approach 예시 - 전문가
- Named-Entity Recognition(NER) / Relation Extraction(RE) : 문장 내의 entity, relation 을 구분하는 task
- Natural Language Inference (NLI) : Hypothesis가 premise 와 일치하는지를 판단하는 task
- Question Answering : 주어진 question에 맞는 answer를 생성 또는 선택하는 task - Unsupervised Learning Approach 예시 - 모두 (우리, 군중
- Language Model (LM) : 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당(assign)하는 모델
뉴럴심볼릭( Neural Symbolic ) 기반 자연언어처리
- 사전에 구축된 상식 정보를 지식 그래프 형태로 구축하여 딥러닝 모델에 주입
⇒ 상식정보, 추론 능력 등 딥러닝 모델의 한계를 보완
- 뉴럴심볼릭 방법의 접목
- 논리적 추론 영역에서는 지식 표현이 이산적 특성을 갖기 때문에 numerical 모델에는 한계
⇒ 지식 베이스의 심볼지식을 Neural Network에 내재화해 지식 베이스를 확장 - 다양한 분야의 Knowledge Graph와 결합
- Knowledge Base Question Answering
- KGBERT
- Knowledge graph의 triples를 textual sequence로 인식 ⇒ 이러한 triples를 만들기 위해 KG-BERT 제안
- input : entity, relation description of a triple → computes scoring function of the triple
- 결과 : triple classification, link prediction, relation prediction tasks에서 SOTA - Common Sense Knowledge Graph
- 인간의 상식이나 지식에 기초해 작은 학습데이터로 많은 추론을 이끔
- 상식을 entity, relation을 활용한 지식 베이스 그래프 형태로 표현 Ex) 어떤 사람이 상점에 간다(PersonX goes to the store) - Multi-hop Question Answering
- 질문과 함께 거대한 지식 코퍼스가 주어졌을 때 답을 찾기 위해 말뭉치에 다중추론 점프(홉)를 수행하여 질문에 답하는 것
- Entity 중심의 relation graph를 활용해 Multi-hop reasoning이 필요한 Question에 대한 응답을 추출
Pretrain-Finetuning 기반 자연언어처리
- Language Model
- 대중이 만든 데이터(Pre-train) + 전문가가 만든 데이터(Fine-tune)
- 대량의 말뭉치로 언어 능력을 pre-training 이후 task-specific fine-tuning - Pretraining
- 내가 원하는 task 이외의 다른 task의 데이터를 이용하여 주어진 모델을 먼저 학습하는 과정 - Finetuning
- 사전학습된 모델을 원하는 task에 해당하는 데이터, 학습 방식으로 다시한번 재학습 시키는 과정 - 벤치마크의 등장
- Task-specific benchmark dataset 대량 등장
- Leaderboard에서의 성능 경쟁 - Transformer의 등장 이후로 NLP 연구의 메인 트렌드
- 다양한 Transformer variants 연구도 활발해짐
- Vanilla Transformer를 바탕으로 Encoder만 사용하는 BERT family, Decoder만 사용하는 GPT family, Encoder-Decoder(Seq2Seq)구조를 가지는 BART family, Transformer XL family 등
- 다양한 pre-training task (mask, denois, ..)
- 다양한 training corpus, parameter, .. - Language Model 계보
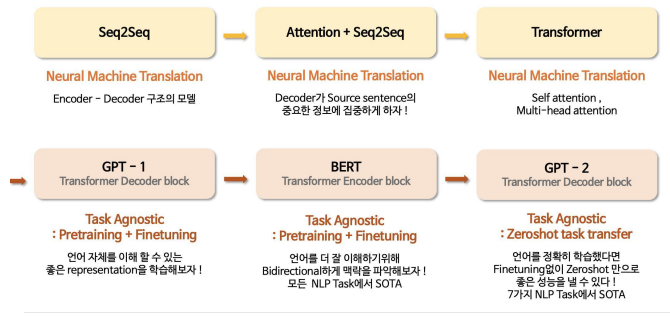

LLM( Large Language Models )기반 자연언어처리
- Scaling Laws for Neural Language Models (OpenAI)
- 모델 사이즈 => Larger is Better ⇒ Model size > Batch size > Steps
- NLM의 성능은 훈련 시간, 문장 길이, 데이터 크기, 모델 크기, 연산 능력과 멱법칙 관계 ⇒ 데이터 양보다 모델 사이즈가 성능에 일관적으로 더 큰 영향을 미치며, 큰 모델이 좋음을 증명 “Upscaling” - 영향력
- 대규모 언어 모델의 등장
- 국내 및 국외 다양한 기업이 자신만의 LLM 개발
- 새로운 직군의 등장 = Data의 중요성
- 검색의 새로운 패러다임 : 기존 SOTA 모델들이나 검색 시스템과 확연한 차이, 탐색에서 생성으로 검색의 관점이 전환
- 의식적 데이터 생성 = 피드백
- Foundation Models
- In-Context Few-Shot Learning & Prompt Learning
- Prompt Engineering : 다양한 능력을 가진 ChatGPT 그 중심엔 Prompt Engineering - Large Language Models의 예시
- OpenAI의 GPT3
- Google의 PaLM
- Meta의 LLaMA, LLaMA2
- Open AI의 DALL-e
- Kakao Brain의 KoGPT, Min DALL-E
- Naver AI Lab의 HyperCLOVA
- LG AI Research의 EXAONE
- ChatGPT
Continual Learning

Ethics & Fairness
- 문제점
- Fairness AI의 부상 : 이루다의 문제
- Fairness NLP: 현실의 데이터 셋에서 머신 러닝 모델이 판단을 내리는 데에 bias를 최소화 시키는 것을 목표로 연구 분야
- ChatGPT 조차 무결성을 보장하지는 못함
- 문화적 차이
- 사회적 인식에 따른 편향 - NMT에서의 대응 방안
- 오역에 의해 변질된 의미로 인한 경제적 손실 및 위법 가능성, 안전에 대한 잘못된 정보 제공의 위험, 종교나 인종 또는 성차별적 발언에 의한 파장은 실생활과 문제가 직결됨
- 이러한 문제를 완화하기 위해, 기계번역 품질 예측 분야에서는 치명적 오류 감지(Critical Error Detection, CED)에 대한 연구가 이루어지고 있음
'Study > 자연언어처리 NLP' 카테고리의 다른 글
| 자연언어처리의 연구와 서비스 (1) | 2025.01.13 |
|---|---|
| 딥러닝 기반의 자연언어처리 (0) | 2025.01.13 |
| 자연어처리-응용시스템 (0) | 2025.01.13 |
| 자연언어처리 - 텍스트 전처리 (0) | 2025.01.12 |
| 자연언어처리 - 언어학 (1) | 2025.01.10 |