딥러닝 학습방법 - 신경망 레이어의 출력 값은 레이어를 구성하는 가중치(파라미터)들의 값에 의해 결정 - m개의 입력을 받아 n개의 값을 출력하는 완전연결층은 m×n개의 입력 가중치 값과 n개의 편향 가중치(bias) 값이 있음 - 딥러닝 모델들에는 입력 데이터와 출력 데이터를 처리하기 위해 보통 수천개 이상의 파라미터가 사용되고, 레이어의 수도 수십에서 수백에 이름 - 이 외에도 모델의 여러 특성들을 결정하는데 가중치 값들이 사용됨 딥러닝 모델은 수천만에서 수억, 수십억 개 이상의 가중치들로 이루어져 있음
- 원하는 출력을 만들어내기 위해서는 모든 파라미터의 값을 정밀하게 조정해야 함 - 딥러닝은 파라미터에 따라 매우 다양한 입력-출력을 학습 가능함 - 딥러닝에서의 학습은 수많은 파라미터들의 최적 값을 찾아가는 과정을 의미함
계산방향 - 정방향 계산(forward pass)은 입력으로부터 예측을 만들어내는 과정을 의미함 - 역방향 계산(backward pass)은 예측과 정답 사이의 차이를 줄이는 방향으로 파라미터를 수정하는 과정을 의미함 - 출력에서 입력으로 계산이 역방향으로 진행되기 때문에 역전파(back-propagation)라고 함
손실함수 - 손실 함수(loss function)는 모델의 예측과 정답 사이의 차이를 수치화시켜주는 함수 - 손실 함수의 값을 각각의 파라미터들에 대해 편미분하면 그래디언트(gradient)를 계산할 수 있음
- 그래디언트에 따라 파라미터들을 수정하면, 현재 입력에 대한 모델의 예측이 정답에 가까워짐 - 이러한 과정을 모든 데이터에 대해 반복적으로 적용 - 딥러닝 모델에서 손실 함수에 대한 입력층의 그래디언트는 편미분의 특성상 한 번에 계산할 수 없음 - 손실 함수에 대한 출력층의 그래디언트를 계산하고, 이로부터 다시 이전층의 그래디언트를 계산하는 방식으로 연쇄 법칙 (chain rule)을 이용
미분값 - 딥러닝 모델의 학습에는 미분값이 큰 영향을 미치며, 손실 함수로부터 편미분값을 계산할 수 있는 가중치들만 역전파 알고리즘을 이용하여 값을 학습할 수 있음
RNN
Sequence-to-sequence - 입력된 시퀀스(문장)을 다른 시퀀스로 변환하는 모델로, 인코더 RNN과 디코더 RNN로 구성
- 인코더 (Encoder) : 입력 시퀀스를 받아들여 고정된 길이의 벡터로 변환함 - 이 벡터는 입력 시퀀스의 정보를 압축적으로 담고 있음 - 이 벡터를 문맥 벡터(context vector)라고 부름 - 디코더 (Decoder) : 문맥 벡터를 받아들여 출력 시퀀스를 생성 - 디코더는 문맥 벡터와 이전에 생성한 출력을 기반으로 다음 출력을 생성함
Recurrent Neural Networks (RNNs)
- RNN의 종류
- RNN 변형
장점 - 모든 길이의 시퀀스를 입력으로 처리 가능 - 시간에 따라 가중치를 공유하여, 입력 시퀀스가 길어져도 모델 크기가 증가하지 않음 - 과거 정보를 고려하여 다음 시간의 출력을 계산함
단점 - 매번 시간에 따라 출력을 계산하므로, 병렬 처리가 불가능하여 계산 속도가 느림 - 입력 혹은 출력 시퀀스가 길어지면 오래전 정보를 반영하기 어려움 (Long-term dependency) - 현재 상태에 대한 미래 입력을 고려할 수 없음
LSTM & GRU - Gradient vanishing / exploding - RNN의 역전파 과정에서 그래디언트가 너무 작아져서(gradient vanishing) 가중치 업데이트가 잘 안 되거나, - 그래디언트가 너무 커져서(gradient exploding) 가중치 값이 엄청나게 커지는 문제가 발생 -> 모델이 불안정해지고, 시퀀스 데이터의 장기 의존성을 제대로 학습하지 못하게 됨
- Long Short-Term Memory (LSTM)
- RNN에서 발생하는 Long-term dependency problem 완화 방법으로 LSTM은 cell state와 gate라는 메커니즘을 도입 - 필요한 정보만을 선택적으로 업데이트하거나 삭제하는 방법을 도입 (정보를 잘 기억하고 활용) - sigmoid 활성화 함수 : 출력 값의 범위를 [0, 1]로 제한하여, 게이트에서 어떤 정보를 통과시킬지 결정하는 데 사용됨 -현재 시간 단계에서의 cell state 후보 : 현재 입력과 이전 hidden state에 기반하여 계산됨 - 현재 시간 단계에서의 cell state :forget gate가 결정한 대로 이전 cell state의 일부를 잊고, input gate가 결정한 대로 새로운 정보를 추가하여 업데이트됨 - forget gate, input gate, output gate : 이전 cell state의 어느 부분을 잊을지, 새로운 정보를 얼마나 추가할지, 어느 부분을 hidden state로 출력할지 결정
- Forget gate : forget gate layer로, 이전 cell state의 어느 정보를 버릴지 결정 와 는 학습 가능한 가중치와 편향 - 시그모이드 함수 sigmoid는 출력을 0과 1 사이로 제한하여 어떤 요소를 완전히 잊어버릴지(0) 또는 완전히 기억할지(1) 결정 - Input gate : input gate layer로, 어떤 새로운 정보를 cell state에 저장할지 결정 - 새로운 후보 cell state를 생성. 이후에 후보 cell state 정보 중 일부가 cell state에 저장 - Cell state : cell state 업데이트 - 먼저 forget gate를 통해 결정된 정보를 잊어버린 다음, input gate에서 결정된 정보를 추가 - Output gate : output gate로, 다음 hidden state가 무엇을 출력해야 하는지 결정 - output gate 값과 현재 시간단계의 cell state 값을 통해 현재 hidden state를 계산
Gated Recurrent Unit (GRU) - GRU(Gated Recurrent Unit)는 LSTM(Long Short-Term Memory)의 변형으로, 더 간단한 구조를 가짐 - LSTM의 세 가지 게이트(forget, input, output)와 두 개의 상태(cell state, hidden state)에 비해, GRU는 두 개의 게이트(update, reset) 와 하나의 상태(hidden state)만을 가짐 - 더 간단한 구조로 계산 효율성이 높음 - cell state가 없으므로 LSTM 대비 Long-term dependency에 취약
- update gate : 현재 hidden state를 얼마나 업데이트할지 결정 - reset gate : 이전 hidden state를 얼마나 '잊어버릴지' 결정 - 새로운 후보 hidden state를 계산 - 후보 hidden state를 통해, 현재 hidden state를 업데이트
Attenion
Attention - 사람은 글을 읽을 때 모든 단어들 집중해서 읽지 않음. 중요하다고 생각하는 단어에만 집중을 하고 나머지는 그냥 읽음 => 주목도가 다르다! - Attention이란 문맥에 따라 집중할 단어를 결정하는 방식으로 문맥을 최대한 고려할 수 있는 핵심 방식 - 시퀀스의 길이가 길 수록 attention이 없으면 성능이 저하 → Long-Term Dependency Problem
- RNNsearch : Attention이 포함된 RNN 모델 - RNNenc : Attention이 포함되지 않은 RNN 모델 -인코더의 hidden state를 디코더로 전달 (기존의 seq2seq은 context vector만 전달) -각 hidden states에 점수를 계산하여 디코더가 생성 시간 별로 집중할 부분을 찾음 -여러 time steps에서 모델이 입력의 다른 부분에 ‘집중 (focus)’하도록 함
- Key = Value: 인코더의 각 hidden state - Query: 현재 time step 시점의 디코더의 hidden state - Attention function: Query와 Key 사이의 유사도를 계산하는 함수 - Attention scores: 각 hidden state의 중요도를 결정하는 점수 - Attention distribution: Attention scores를 Softmax 함수로 확률 분포로 변환한 분포
Attention functions
Attention map-디코더의 각 시점마다 인코더의 각 단어와의 Attention score를 시각화한 것 - ‘home’을 번역하는 시점에서 ‘casa’의 score가 높음
RNN with Attention
- Encoder - Decoder 구조에서 각각의 output이 hidden state의 형태로 출력 - Encoder의 경우 모든 RNN 셀의 hidden states들을 사용하는 반면, Decoder의 경우 현재 RNN셀의 hidden state만을 사용 - Encoder hidden states: Source sequence의 문맥(모든 문맥을 활용) - Decoder hidden state: Target sequence의 문맥
- Encoder hidden states와 Decoder hidden state을 이용해 Attention score를 구함. (해당 경우 score1 ~ score4까지 4개) - Attention score들을 softmax function에 대입해 각 score들의 중요도의 상대성을 연산(확률화) - Encoder hidden states X Attention score ⇒ 각 문맥들(hidden states)의 중요도(Attention score) 를 반영하여 최종 문맥(Attention value)을 산출
- Attention 모듈을 사용해 디코딩시 어떤 인코더의 토큰에 주목할지를 고려 - Decoder는 디코딩 시 매 Time-Step 별로 새로 생성될 토큰을 결정할 때 Source Sequence에서 가장 가까운 관계의 토큰을 결정하고, 이 정보를 활용하는 구조
Transformer Encoder - Input Embeddings - Input Embeddings는 입력 데이터를 고차원 벡터로 변환하는 과정을 의미 - 모델이 입력 데이터를 처리할 수 있도록, Vocabulary를 연속적인 벡터 형태로 변환 - Input Embeddings는 학습 가능한 파라미터들로 구성됨
- Positional Encoding : 문장 내 단어의 순서 정보를 모델에 제공하는 방법
- Positional Encoding이라는 과정을 통해 단어의 위치 정보를 포함할 수 있음 - 이는 모델이 문장 내에서 단어의 순서를 이해하고, 이를 바탕으로 더 정확한 예측을 수행할 수 있게 함 (dogs ≠ #dogs) - RNN에서는 Recurrent한 반복으로 단어 순서 정보를 반영했다면, Transformer는 Positional Encoding으로 단어의 위치 정보를 반영 (병렬적 연산 가능)
- Self-Attention - 기존 Seq2seq에서 Attention : 입력 문장과 타겟 문장 사이의 Attention Score만 계산 - Transformer의 Encoder 혹은 Decoder에서의 Self-Attention : 입력 문장 내의 토큰들의 attention
- 1단계 • 3개의 Query, Key, Value 벡터를 구성 - 2단계 • Query와 Key를 곱하여 Dot Product Attention Score 계산 - 3단계 • Scale 작업을 진행함. Key 벡터사이즈인 64의 제곱근인 8로 나누어 줌 - 4단계 • Softmax를 진행. 현재 위치의 단어의 encoding에 있어서 얼마나 각 단어들의 표현이 들어가는지에 대한 일종의 확률 값으로 변환 - 5단계 • Softmax를 통과한 확률 값을 Value 벡터의 각각 원소에 곱하여 새로운 벡터를 얻음. 지금까지의 과정을 Scaled Dot Product Attention이라 명명함 - 6단계 • 결과로 나온 벡터를 다 더하여 Self Attention의 출력을 구성
- Query = Key = Value - 현재 time step 시점의 모든 hidden states - 이전의 Attention 메커니즘은 Query ≠ Key = Value
- Multi-Head Attention → 여러 self-attention의 앙상블 - 여러 개의 Self-Attention을 계산 - 여기서 각 head는 다음과 같이 계산됨 - Attention은 self-attention을 의미 - Self-Attention 계산 과정을 8개의 다른 weight 행렬들에 대해 Head 갯수 만큼 수행 - Transformer 논문에서는 Head를 8개로 나누어서 계산 - 다양한 표현을 학습함으로 더 잘 표현할 수 있음
- 1단계 : Thinking Machines라는 문장 X가 입력되면, Input Embedding 및 Position Encoding을 거쳐 입력벡터 계산 - 2단계 : 입력벡터를 통해 Self-Attention을 HEAD #0 - #7 까지 모두 계산 - 3단계 : 계산된 Self-Attention 값들을 가지는 모든 HEAD들을 연결 - HEAD # 0 — HEAD # 7의 출력인 Z_0 ~ Z_7 값들을 연결 - 4단계 • 연결된 Z0 – Z7의 값을 최종 Output Matrix인 와 곱하여 최종 벡터 를 계산
- Addition & Layer Normalization - Addition: 두 개 이상의 텐서를 요소별로 더하는 연산 - Transformer 모델에서는 각 계층의 입력과 출력을 더하는 - Residual Connection 기법을 Addition으로 사용 - 이는 모델의 깊이가 깊어질수록 발생할 수 있는 Over-fitting 문제를 완화하는 데 도움을 줌 - Layer Normalization: 각 layer의 출력을 정규화하는 방법 - Layer Normalization은 각 샘플의 특성 값들을 평균 0, 분산 1로 정규화
- FFNN: Feed-Forward Networks - Position-wise Feed-Forward Network (FFN) : 각 위치에서 독립적으로 동일하게 적용되는 두 개의 선형 변환으로 구성 - 이는 모델이 각 단어를 독립적으로 처리하면서도, 전체 문장의 문맥을 고려할 수 있게 함
Transformer Decoder -Causal Attention
- 입력된 토큰까지의 정보만 Attention에 반영하고, 미래의 입력은 반영하지 않는 것 - 일반적인 Attention 메커니즘은 입력 시퀀스의 모든 위치에 접근하여 현재 위치의 출력을 계산할 때 이전 뿐만 아니라 이후의 정보도 사용함 - 문장 전체의 문맥을 이해하는 데 유용하지만, 미래의 정보는 아직 알 수 없어야 하기에, 실시간 처리나 예측 작업에서는 문제가 됨 - 이 문제를 해결하기 위해 Causal Attention이 도입됨
- Encoder-Decoder Attention
- Decoder가 출력 시퀀스의 각 요소를 생성할 때, 입력 시퀀스의 모든 요소를 고려할 수 있게 함 - Decoder는 입력 시퀀스의 각 요소와의 attention score를 계산하고, 이를 기반으로 입력 시퀀스의 가중 평균을 구함
- Linear & Softmax
- 최종 Decoder stack의 출력 벡터를 vocabulary 사이즈로 변환. 여기서, vocabulary 사이즈와 동일한 벡터의 사이즈로 변환하기 위해 Linear layer 사용 변환된 값을 logits 이라 함 - 이를 softmax를 통해 확률 값으로 변환 후에 가장 높은 확률 값을 가지는 단어(토큰)을 다음 출력 토큰으로 생성
응용분야
딥러닝 기반 사전학습 모델 (Pretrained Language Model) - BERT(Bidirectional Encoder Representations from Transformers)
- BERT는 사전 학습된 대용량의 레이블링 되지 않는 데이터를 이용하여 학습된 언어 모델 - Transformer의 인코더 구조만을 사용 - 문장이 주어졌을 때 문맥을 양방향으로 보는 bidirectional한 특징으로 높은 성능 - 두 가지 하위 태스크로 학습 - MLM(Masked Language Modeling): 주변 문맥을 토대로 빈칸에 올 단어 찾기 - NSP(Next Sentence Prediction): 연속된 문장인지 아닌지 분류 - 문장 정보 주입을 위해 총 3가지 Embedding 사용 - Token Embedding: 실질적인 텍스트가 입력 • Segment Embedding: 두 개의 문장을 구분 - Position Embedding: 위치 정보를 학습
- GPT-2(Generative Pretrained Transformer 2) - GPT-2는 사전 학습된 대용량의 레이블링 되지 않는 데이터를 이용하여 언어 모델을 학습한 언어 모델 - GPT-2는 BERT와 달리 Transformer의 디코더 구조만을 사용 - 문장이 주어졌을 때 문맥을 단방향(왼쪽에서 오른쪽)으로 보는 특징 - 하나의 태스크로 학습 : CLM(Causal Language Modeling): 주변 문맥을 토대로 다음에 올 단어 예측 - 문장 정보 주입을 위해 총 3가지 Embedding 사용 - Token Embedding: 실질적인 텍스트가 입력 - Segment Embedding: 두 개의 문장을 구분 - Position Embedding: 위치 정보를 학습
- BART(Bidirectional Auto Regressive Transformers)
- Bidirectional: BERT의 양방향 문맥을 모두 보는 특성 - Auto Regressive: GPT의 다음에 올 단어를 예측하는 단방향 특성 - 두가지 특성을 결합해 Encoder-Decoder 구조를 갖는 대규모 사전학습 Seq2Seq 모델 - 임의로 변형된 문서를 원래대로 되돌리는 denoising autoencoder로 문서의 손상을 복원하도록 학습
- BART Pretraining
- Token Masking BERT의 MLM과 동일한 방법으로 random tokens들이 추출되어 [MASK] 토큰으로 대체 - Token Deletion 어느 위치에서 토큰이 삭제가 되었는지 맞춤 - Text Infilling text spans을 샘플링하고, 이를 단일 [MASK] 토큰으로 대체 - Sentence Permutation 문장 간의 순서를 바꾸어 올바른 순서를 복원하도록 학습
- MLM (Masked Language Modeling) - NSP (Next Sentence Prediction)
딥러닝 기반 형태소 분석 & 품사 태깅
- CNN 방식의 형태소 분석과 품사 태깅
- LSTM, RNN 같은 시퀀스 정보를 인식하는 인공 신경망에 비해 속도면에서 좋은 성능을 내는 CNN - 입력 : 문장의 음절, 윈도우 크기만큼 좌/우로 확장한 문맥 사용 - 커널의 크기가 3인 4개의 필터를 사용한 컨볼루션: 커널 크기 2, 3, 4, 5에 대해 각각 길이가 4인 벡터를 연결하여 총 길이 16인 벡터를 생성하고 은닉, 출력층을 거쳐 최종적으로 태그가 결정
- Character-Level Bidirectional LSTM-CRF - Character-Level LSTM은 각 문자를 입력으로 받아 문자열의 특성을 학습함 - Bidirectional LSTM은 두 개의 LSTM을 사용하여 입력 시퀀스를 양방향으로 처리함 - 학습된 문자열 특성은 CRF 모델에 입력됨 - CRF는 시퀀스 데이터의 각 요소에 레이블을 할당 하는 데 사용되는 확률 모델 - 여기서는 각 형태소의 품사를 예측하는 데 사용
딥러닝 기반 의미역 분석
- 문장 내 어절의 의미를 고려하여 역할을 분류 - 의미역 결정(Semantic Role Labeling)을 통해 문장 내의 서술어와 서술어의 수식을 받는 문항 간의 의미를 분석하고, 역할을 분류함 - 의미역 결정은 문장의 의미를 더 깊게 이해하고, 문장 내에서 각 단어나 구문이 어떤 의미를 가지는지 파악하는 데 도움을 줌
- BERT를 이용한 한국어 의미역 분석 - 여러 개의 Transformer layer를 쌓은 양방향 인코더인 BERT 모델을 이용하여 기존의 의미역 분석보다 높은 성능을 보임 - BERT의 결과를 LSTM-CRF의 입력으로 사용하여 의미역 문제를 해결
딥러닝 기반 개체명 인식
-NER 시스템 (1) Distributed Representations for Input - 인풋 데이터를 벡터 등으로 표현하는 층으로 Pre-trained word embedding, Character-level embedding, POS tag, Gazetteer 등을 이용 (2) Context Encoder -문맥 정보를 인코딩하는 층으로 CNN, RNN, Transformer 등의 모델을 이용 (3) Tag Decoder -태그 정보를 디코딩하는 층으로 Softmax, CRF, RNN, Point network 등의 모델을 이용 -딥러닝 기반 개체명 인식
-문장의 각 단어는 RNN기반 모델에 입력으로 주어짐 -이때 각 단어는 단어 임베딩으로 표현되어 숫자 형태로 변환됨 -그림에서는 LSTM (Long Short Term Memory, LSTM)을 사용하는 모델을 보여줌 -LSTM은 RNN의 한 종류로, 장기 의존성 문제를 해결하기 위해 설계됨 -"New York is a long way"라는 문장은 단어 단위의 임베딩으로 변환되어 모델에 입력됨
딥러닝 기반 질의응답 - Machine Reading Comprehension
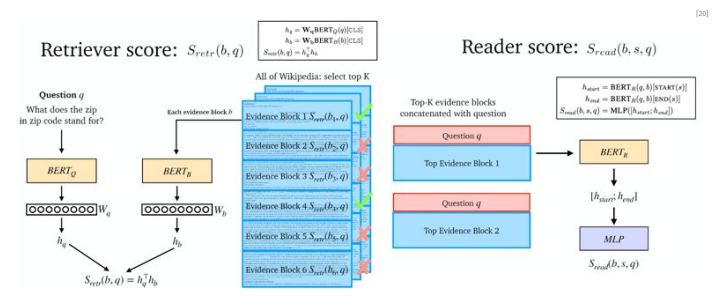
- Dense Passage Retrieval
- Document Reader - IR시스템에서 전달받은 문서들을 Reader에게 전달 - Reader 모듈은 입력받은 문서와 질의를 바탕으로 올바른 정답으로 추정되는 문구(span)의 위치 확률을 계산 - Information Retrieval to Reader
- 딥러닝 기반 질의응답 - 샴 네트워크 기반의 질의응답 모델은 문장의 의미 유사도를 판단하거나 문장을 식별하는 등의 작업에 활용되는 모델 - 입력된 문장은 동일한 구조의 인코더 계층을 통해 벡터 표현으로 변환됨 - 변환된 두 문장은 코사인 유사도, element-wise 연산 또는 신경망 기반의 가중합을 통해 질문과 정답 후보 간의 연관성 점수를 계산함 - 장점은 구조가 단순하다는 것이지만, 단점은 인코더 계층에서 질문과 정답 후보 간의 상호작용이 고려되지 않음 - 어텐션 메커니즘 기반 네트워크는 샴 네트워크의 단점을 보완하여, 질문과 정답 후보 간의 상호작용을 반영한 모델 - 질문과 정답 후보 문장은 각각 양방향 LSTM과 풀링 계층을 통해 표현됨 - 어텐션 메커니즘으로 정답 후보 문장의 표현을 생성할 때는 질문 표현으로부터 생성된 가중치가 곱해짐
딥러닝 기반 기계번역
- 신경망 기반 기계 번역(NMT: Neural Machine Translation)
딥러닝 기반 문서요약 - 추출 및 생성 요약 - BART Summarization - KoBART
- BERTSum
- Summarization에 BERT pretraining -> fine-tuning 방식을 적용 - Pretrained BERT를 이용해 source text의 representation을 추출한 뒤 이를 사용하는 Transformer 기반 추출 및 추상 요약 모델 - 각 문장 앞에 [CLS] 토큰을 통해 해당 문장이 요약에 사용되는 문장인지 아닌지를 구분하도록 학습함 => 전체 문서에서 주요 문장을 판별하는 효과
- BERTSUMEXT : pretrained BERT 위에 Transformer model을 추가해 추출 요약 - BERTSUMABS : pretrained BERT 위에 Transformer decoder model을 추가해 추상 요약 - BERTSUMExtABS : 앞선 두 개의 방식을 모두 채택하여 추출 요약을 수행한 후에 추상 요약
- Sequence-To-Sequence Pre-training (STEP) - Seq2Seq 기반의 문서 요약 모델을 사전 학습하는 세 가지 방법을 제시 - Sentence Reordering (SR) • 문서를 여러 문장으로 나누고, 문장의 순서를 섞어 새로운 문서를 생성하고, 원래의 문서를 복원하도록 학습 - Next Sentence Generation (NSG) • 문서의 한 부분을 사용하여 그 다음 부분을 예측하도록 모델을 학습 - Masked Document Generation (MDG) • 특정 토큰 범위를 마스킹한 문서를 복원/특정 토큰을 [MASK], 무작위 토큰으로 대체하거나, 그대로 둠
- PEGASUS
- Pre-training with Extracted Gap-sentences for Abstractive Summarization - Gap Sentences Generation (GSG) - 입력 문서에서 요약과 유사한 텍스트를 생성하는 것을 포함. 문서에서 전체 문장을 선택하고 마스크하며, gap 문장을 의 사 요약으로 연결 - 세 가지 주요 전략을 고려하여 문서에서 m개의 gap 문장을 선택 - Random: 무작위로 m개의 문장을 선택 - Lead: 처음 m개의 문장을 선택 - Principal: 중요한 상위 m개의 문장을 선택 - Masked Language Model (MLM) : BERT와 동일
딥러닝 기반 대화모델 - Dialogue System - Task-Oriented Dialogue (TOD) VS Open-domain Dialogue (ODD)
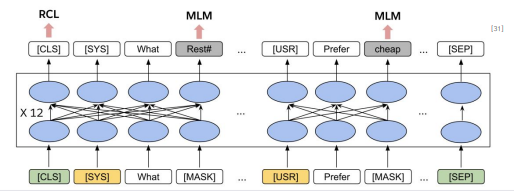
- TOD-BERT
- BERT 아키텍처 기반 - Mask Language Model (MLM)과 Response Contrastive Loss (RCL) 두 가지 손실 함수를 사용하여 훈련 - MLM은 BERT와 동일 - RCL은 두 문장 세그먼트 A, B를 연결하여 Negative sample을 생성하여 대조 손실 학습