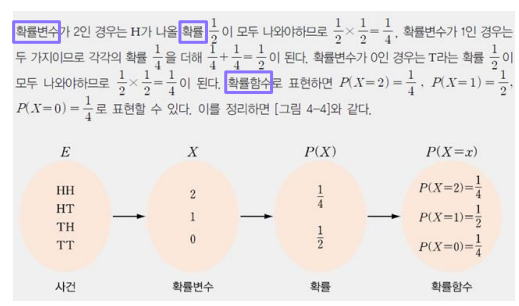
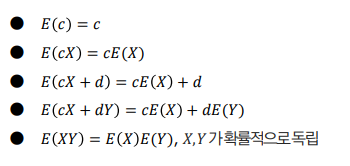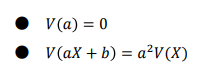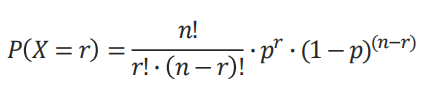확률변수 - 확률변수란 확률적 시행의 결과(사건)를실수로 대응시키는 함수 - 확률변수가 특정값을 가질 확률을 나타내는 함수
-이산확률변수: 수집한 데이터의 확률변수중에서 셀 수 있는 값들로 구성되거나 일정한 범위로 나타낼 수 있는 확률변수 - 이산확률 변수의 확률 함수: 이 경우 확률함수는“확률질량함수(PMF, Probability Mass Function)” 이산 확률변수𝑋가 특정값𝑥를 가질 확률𝑃(𝑋 = 𝑥)를 나타냄 PMF는 다음 조건을 만족해야함: 0 ≤𝑃(𝑋 = 𝑥) ≤1 가능한모든값에대해확률의합이1이어야함. 즉, σ 𝑃 𝑋 = 𝑥 = 1
-연속확률변수: 연속형 또는 무한한 경우와 같이 셀수없는 확률변수 - 연속확률 변수의 확률함수: 연속 확률 변수에서는“확률밀도함수(PDF, Probability Density Function)”를 사용하여 특정 구간에서 확률 변수가 나타날 확률 - PDF는 특정값에서의 확률을 직접적으로 구할 수는 없고, 특정 구간에서의 확률을 적분하여 계산함 확률밀도함수𝑓(𝑥)는 다음 조건을 만족해야 함: 𝑓(𝑥) ≥ 0 확률변수 전체 구간에서의 확률은 1이어야 함
사건, 확률변수, 확률, 확률 함수의 관계
확률변수의 평균 = 기대값 - 어떤사건에 대하여 해당 사건이 벌어질 확률을 곱해서 전체 사건에 대하여 합한 값을 의미
- 성질
확률변수의 분산 = 기대값의 특성을 나타내는 값 - 확률변수들이기대값으로부터벗어난정도 - 기대값과 어느 정도 차이가 있는지를 나타냄
- 확률변수의 분산의 성질
- 확률변수의 표준편차 : 표준편차는분산(𝜎 2 )의제곱근
Probability Distribution 확률분포
확률변수가 가질 수 있는 모든 가능한 값과 그 값들이 발생할 확률을 나타낸 것을 의미
일반적으로 확률분포는 표나 그래프 표상으로 나타냄
균등분포 : 확률변수가 특정 구간 내에서 동일한 확률로 모든 값을 가질 수 있는 분포 - 이산 균등분포 : 이산 확률 변수가 가질 수 있는 몇가지 가능한 값들이 동일한 확률로 나타나는 확률 분포 - 연속 균등분포 : 연속 확률 변수가 특정 구간 내에서 동일한 확률 함수를 가지는 분포
정규분포 : 표본분포 중 가장 단순하면서 많이 나타나는 형태의 분포 - 중심 극한 정리 : 사건이 일어난 빈도(를 계산하여 그래프로 나타내면 중심(평균)을 기준으로 좌우가 대칭되는 분포가 그려짐 - 평균이𝑚, 분산이𝜎 2인 정규분포의 확률함수는 𝑒 = 2.71828…인 무리수를 사용
- 정규분포의 성질 1) 어떤 실수 x에 대해 f(x)>0 2) 분포곡선은 평균 m을 기준으로 좌우대칭 3)곡선과 x-축 사이의 넓이는 1 4)곡선 내 임의의 a,b가 a<b일 때 a와 b에 속할 확률 P(a≤X≤b)는 a,b 곡선 사이의 넓이와 같다.
- 표준 정규 분포 : 평균이0, 표준편차는1을기준으로 각각의 정규분포들을 표준화한 정규 분포를 의미 - 확률변수𝑋가 정규분포𝑁(𝜇,𝜎 2 )을 따를 때, 새로운 확률 변수𝑥−𝜇 𝜎 = 𝑧로 변환하면,
- 확률변수 𝑍의 값이 (0, 𝑧)에 속할 확률은 아래의 넓이와 같음 ( 즉, 𝑃(0 ≤ 𝑍 ≤ 𝑧) )
- 표준정규분포 : 정규분포를 표준화하여 평균과 분산을 구하는 과정은 다음과 같음
정규분포 출력 실습
import numpy as np
import matplotlib.pyplot as plt
mu, sigma = 0, 0.1 # 평균 mu, 표준편차 sigma
s = np.random.normal(mu, sigma, 1000) # 1000개의 샘플을 생성
count, bins, ignored = plt.hist(s, 30, density=True) # 히스토그램을 그리기
plt.plot(bins, 1/(sigma*np.sqrt(2*np.pi))*
np.exp(- (bins - mu)**2 / (2*sigma**2)), linewidth=2, color='r') #정규분포의 확률밀도함수를 그래프로 그리는 작업
plt.show() #출력
import numpy as np
import matplotlib.pyplot as plt
mu = 0 # 평균과 표준편차 설정
sigma = 0.1
x = np.linspace(mu - 3*sigma, mu + 3*sigma, 1000) # 충분히 넓은 범위의 x값 설정
pdf = 1/(sigma * np.sqrt(2 * np.pi)) * np.exp(-0.5 * ((x - mu) / sigma)**2) # 정규분포의 확률밀도함수 계산
plt.plot(x, pdf, linewidth=2, color='r') # 선 그래프로 PDF 그리기
plt.title('Normal Distribution PDF')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.show()
import numpy as np
import matplotlib.pyplot as plt
data = np.random.binomial(n=10, p=0.5, size=1000) # 이항 분포 데이터 생성
values, counts = np.unique(data, return_counts=True) # 각 결과값의 빈도 계산
plt.plot(values, counts, marker='o', linestyle='-') # plt.plot을 사용하여 선 그래프 그리기
plt.xlabel('Number of Successes')
plt.ylabel('Frequency')
plt.title('Binomial Distribution (n=10, p=0.5)')
plt.grid(True)
plt.show()
베르누이 시행 : 서로 반대되는 사건이 일어나는 시행을 반복적으로 실험하는 것 - 서로 반대되는 사건이란 반드시 두가지만 존재하며 동시에 일어나지 않는 배타적인 사건을 의미함 - 동전던지기가 대표적인 베르누이 시행
- 베르누이 분포 : 베르누이 시행을 확률 분포로 나타낸 것 - 평균과 분산
이항 분포 : 연속적인 베르누이 시행을 통해 표현된 확률 분포 - 서로 독립적인 베르누이 시행을 𝑛회 반복하여 성공한 횟수를 𝑋라 할 때, 성공한 𝑋의 확률 분포를 이항분포 - 이항분포의 평균과 분산은 다음과 같음
- 이항분포 확률의 계산 : 𝑛번의 시행에서 성공 확률(𝑝)이 𝑟번 나타날 확률 - 𝑛번의 시행에서 𝑟번 관찰되는 것으로 표현 가능
- 이항분포 실습코드
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.distplot(np.random.binomial(n=10, p=0.7, size=1000), hist=True, kde=False) # 이항분포를 따르는 랜덤 데이터의 히스토그램을 생성
plt.show()
Estimation 추정
기술통계와 추리통계 - 통계 : 여러 가지 현상에 대하여 수리적으로 정리, 분석, 예측하는 작업 - 기술 통계: 수집된 자료의 특성을 요약정리하는 것이 목적 - 중심경향도: 평균, 중앙값, 최빈값등 - 산포도: 범위, 분산, 표준편차등 - 추리통계: 분석된 자료를 근거로 모집단의 특성을 추론하는 것이 목적 - 점추정, 구간추정, 가설, 검정통계량등
추정 관련 용어 - 추정: 추정이란 어떠한 정도를 가늠하는 방법으로 수치로 나타내거나, 범위로 나타낼 수 있음 - 점추청: 모수를 어떤 특정 수치로 표현하는 것 - 구간 추정: 모수를 최소값과 최대값의 범위로 표현하는 것 - 추청량: 표본으로부터 관찰된 값을 토대로 특정 모수를 추정하기 위한 함수 또는 공식을 의미함 - 추정치: 추정량을 사용해 실제 표본 데이터에서 계산된 값을 의미함
점추정 : 오차를 수반 할 수 밖에 없다는 약점이 있음 - 점추정의 오차를 최소로 만드는 것이 바람직한 추정이라 할 수 있음 - 바람직한 점추정량 조건 - 평균 제곱 오차(MSE): 평균 제곱 오차가 최소화 되어야함 - 분산이랑 같은가?
- 일치성(Consistency): 표본의 크기가 모집단의 규모에 근접해야 함 - 불편성(Unbiasedness):추정량의 기댓값이 모수와 같아야 함 - 유효성: 추정량의 분산이 최소값이어야함 - 충분성: 추정량이 모수에 대한 모든 정보를 포함해야 함.
구간추정 : 점추정은 명확한 수치를 제공한다는 장점이 있으나 연구자나 조사자입장에서 오차가 커지는 문제가 있음 - 오차를 줄이기 위하여 신뢰도를 제공하면서 상한값과 하한값으로 모수를 추정하는 방법으로 구간추정을 사용 * 신뢰도: 모수를 포함할 확률 의미
신뢰구간 : 상한값과 하한값의 구간으로 표시됨 - 점추정량을 기준으로 상한과 하한을 설정 : 모수가 포함될 확률을 신뢰수준으로 나타냄 - 신뢰수준이란 여러번 표본을 추출했을 때, 계산된 신뢰구간 중 참된 모수를 포함할 확률을 의미함 - 모평균(𝜇)을 추정하고자 할 때, 표본평균을 𝑥ҧ 표준 오차를 𝑆𝐸라 함 - 표준오차 : ‘표본평균의 표준편차’ 여러 번의 표본 추출로 계산된 표본 평균들이 모평균으로부터 얼마나 떨어져 있는 지를 나타내는 값
- 모평균의 신뢰구간
Hypothesis Test 가설 검정
가설 : 주어진 사실이나 연구나 조사하고자 하는 사실이 어떠할 것인지를 주장하거나 추측하는 것 - 모수를 추정하고자 할 때, 모수가 어떠할 것인지를 연구자나 조사자가 주장하거나 추측하는 것
귀무가설 : 입증하고자 하는 가설로, 일반적으로 믿어온 사실을 가설로 설정한 것 - ‘~와 차이가 없다’, ‘~의 효과는 없다’, ‘~와 같다’가 되어야 함
대립가설 : 귀무가설과 반대되는가설로 연구의 목적이 됨 - ‘~와 차이가 있다’, ‘~의 효과가 있다’, ‘~와 다르다’가 되어야함
오류의 종류 - 1종 오류가 더 위험함 - 1종 오류 : 귀무가설이 참임에도 불구하고, 귀무가설을 기각하는 오류 실제로 효과가 없는데도 효과가 있다고 하는 것 (한 제약 회사의 신약이 효과가 없음에도 불구하고, 효과가 있다고 하는 것) - 2종 오류 : 대립가설이 참임에도 불구하고, 대립가설을 기각하는 오류 실제로 효과가 있는데 효과가 없다고 하는 것 (한 제약 회사의 신약이 효과가 있음에도 불구하고, 효과가 없다고 하는 것)
유의수준 : 가설검정에서 귀무가설이 참일 때, 이를 잘못 기각할 확률을 유의 수준 - 오차허용 범위가 5%인 경우 분포, 일반적인 사회과학 연구분야에서 많이 사용함
유의확률 : p-Value라고하며, 귀무가설을 기각할 수 있는 최소한의 확률 - 유의수준을 기준으로 유의확률이 유의수준보다 높으면 귀무가설을 채택하고, 유의수준보다 낮으면 귀무가설을 기각함 - 사회통계학에서는 0.05나 0.01(정밀함이필요한경우)을 기준으로 함 - 유의확률이 작을수록 신뢰구간을 벗어나게 되고 귀무가설은 기각됨
양측검정 : 기각역이 양쪽에 있음
단측 검정 : 기각역이 한쪽 끝에 있는 검정 : 대립 가설이“~보다 크다”인 경우에는 우측 검정
양측검정이 단측 검정보다 위험도가 낮은 것으로 알려져 있음
양측검정은 단측검정보다 더 보수적인방법 : 동일한 유의 수준을 사용할 때, 1종오류를 범할 가능성이 더 낮음. - 단측 검정은 한쪽 끝에 유의수준 전체를 배분하므로, 귀무가설을 잘못기각할 확률이 더 높아짐 - 양측검정은 두 쪽에 나누어 기각역을 설정 : 같은 유의 수준을 사용하더라도 귀무가설을 기각할 기회가 줄어듬
t-test t검정
검정 통계량이 귀무가설 하에서 t-분포를 따르는 통계적 가설 검정법
검정통계량 : 귀무가설이 참이라는 가정하에서 표본 데이터를 바탕으로 계산된 값 - 귀무가설에서 기대되는 값과 얼마나 차이가 있는 지를 나타내는 지표
임계치 : 귀무 가설을 기각하거나 채택하기 위한 한계값을 의미 - 검정통계량을 계산하여 임계치를 기준으로 좌/우 어느 쪽에 있는가에 따라 채택과 기각을 판단함
결과의 해석 : 검정통계량을 계산한 값이 어느 영역에 포함되는 지를 확인하여 가설의 채택/기각 여부를 판단
z분포 : 표본의 개수가 충분히 많을 때, 표준화 과정을 통해 만들어진 정규분포를 표준 정규분포 또는 z분포
t분포 : 표본이 적은 경우 t분포를 사용함
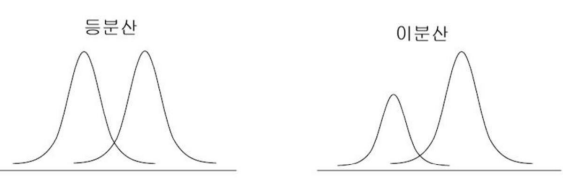
등분산과 이분산 - 등분산 : 2개의 모집단에서 추출된 각 표본 간의 분산이 같음 - 이분산 : 2개의 모집단에서 추출된 각 표본 간의 분산이 다름
단일표본 t검정 - 모집단의 분산을 알지 못할 때 모집단에서 추출된 표본의평균과 연구자나 조사자가 이론적 배경이나 경험적 배경에 의해서 설정한 특정한 수를 비교
Scipy Library : 통계적 분석, 최적화, 신호 처리등 다양한 과학 및 엔지니어링 분야의 계산 기능을 제공
단일표본 t검정 실습 코드
import pandas as pd
from scipy import stats
df = pd.read_csv('단일표본 t 검정 실습.csv', sep=',', encoding='CP949')
from scipy import stats
print(stats.ttest_1samp(df['용량'], 250))
두 종속 표본 t-검정 : 알지 못 하는 각기 다른 두 모집단의 속성인 평균을 비교하기 위하여, 두 모집단으로부터 표본들을 추출하여 표본의 평균들을 비교함으로써 모집단의 평균을 비교하는 통계적 방법 - 두 표본은 서로 독립적인 것이 아니라 어떤 관계가 있는 종속적인 것이야 함
두 종속표본 t검정 실습 코드
import pandas as pd
df = pd.read_csv('두_종속표본_t검정_실습.csv', sep=(','), encoding='CP949')
from scipy import stats
print(stats.ttest_rel(df['복용 전'], df['복용 후']))
두 독립표본 t- 검정 - 각기 다른 두모집단의속성인평균을비교하기위하여, 두모집단을대표하는 표본들을 독립적으로 추출하여 표본의 평균들을 비교함으로써 모집단 의유사성을 검정하는 방법
import pandas as pd
df = pd.read_csv('두_독립표본_t검정_실습.csv', sep=',', encoding='CP949')
from scipy import stats
import numpy as np
class_A = df[df['회사'] == 1]
company1 = np.array(class_A['작동시간'])
class_B = df[df['회사'] == 2]
company2 = np.array(class_B['작동시간'])
stats.bartlett(company1, company2) # 차이가 없으면 등분산 검정
print(stats.ttest_ind(company1, company2, equal_var=True))