분산분석 - 분산의 원인이 어디에 있는가를 알아보는 통계적 방법 - 통계학자이자 생물학자인 로날드 피셔(R. A. Fisher)에 의해서 만들어짐 - 두 개 이상 다수의 집단을 서로 비교하고자 할 때 집단 내 분산을 사용 - 집단 간 분산의 비교를 통해 만들어진 𝐹분포를 이용하여 가설검정을 함 - 3개 이상의 집단에 대한 평균의 차이를 검정하는 분석 방법 - 집단 간 분산과 집단 내 분산을 확인하여 모집단의 특성을 찾아내기에 적합한 분석 방법 - 평균의 차이를 분석하는 방법임에도 불구하고 분산분석이라고 부르게 된 이유는 분산을 비교하여 평균의 차이를 검정하기 때문
- 집단 간의 상대적인 비율을 확인하여 𝑭분산 비율로 나타냄 - 𝐹분산 비율은 집단 간 평균의 차이를 검정하는 검정통계량
- 분산분석을 위한 기본 가정 - 종속변수가 양적변수 - 각 집단에 해당되는 모집단의 분포가 정규분포 - 각 집단에 해당되는 모집단들의 분산이 같아야 함
일원분산분석(one-way ANOVA) - 한가지 기준이 되는 요인으로 비교하고자 하는 변수의 평균 차이가 집단 간에 존재하는 지를 조사하는 것 - 독립변수가 하나일 때 분산의 원인이 집단간 차이에 기인한 것인지를 분석하는 통계적 방법 ( 편의점의 종류를 기준으로 고객의 만족도의 차이를 조사, 국가별 지능의 차이, 등등)
- 일원분석 실습
!pip install pingouin # 라이브러리 설치
import pandas as pd
df = pd.read_csv('일원분산분석_실습.csv', sep=',', encoding='CP949') #데이터 불러오기
import scipy as sp
import numpy as np
import pingouin as pg #pingouin 라이브러리 사용
df1 = df[['store', 'satisfaction']] # 원본 Dataframe‘df’에서 store, satisfaction 두열만 선택하여 새로운 df1을생성
pd.options.display.float_format='{:3f}'.format
store = [] # ‘store’ 열의 값에 따라 ‘statisfaction’값을 그룹화함
for i in range(1, 4): # 여기서는 ‘store’의 값이 1, 2, 3인 경우에 대해 각각의 만족도 점수를 ‘store’ 리스트에저장함
store.append(df1[df1['store']==i]['satisfaction'].values)
sp.stats.levene(store[0], store[1], store[2]) #‘scipy.stats.levene’ 함수를 사용하여 세 그룹의 만족도 점수간 등분산성을 검정
- 원본 Dataframe‘df’에서 store, satisfaction 두 열만 선택하여 새로운 df1을 생성- ‘store’ 열의 값에 따라 ‘statisfaction’값을 그룹화함 - 여기서는 ‘store’의 값이 1, 2, 3인 경우에 대해 각각의 만족도 점수를 ‘store’ 리스트에 저장함 - ‘scipy.stats.levene’ 함수를 사용하여 세그룹의 만족도 점수간 등분산성을 검정
- pingouin 라이브러리를 사용하여‘df1’ 데이터프레임에 대해 일원분산분석을 수행함
* 사후 분석 - 분산분석의 귀무가설은 전체 집단의 평균에 차이가 없다고 말하고 이를 전체가설 -> 일원분산분석에서 귀무가설이기각되고, 대립가설이 채택되었다면 비교 집단들의 모집단의 평균이 차이가 있음을 의미 - 어느 집단과 어느 집단간에 차이가 있는지는 이야기 할 수 없음 - scikit-posthocs는 Python에서 사용할수있는 통계적 유의성검정과 사후 검정을 수행하기 위한 라이브러리
- 데이터프레임 df1 내의 store 열의 데이터 타입을 문자열로 변경 - scikit-posthocs라이브러리의 posthoc_scheffe 함수를 호출하여 Scheffé의 사후 검정을 수행함 - 이때, val_col='satisfaction'는 분석할 값(수치 데이터)이 포함된 열이 'satisfaction'임을 나타내고, group_col='store'는 그룹을 나타내는 열이 'store'임을 지정함
이원분산분석(two-way ANOVA) - 두가지 기준이 되는 요인으로 비교하고자하는 변수의 평균 차이가 집단 간에 존재하는 지를 조사하는 것 - 이원분산분석이 일원 분산 분석과 다른 점은 요인이 두 개라는 것 - 각 요인에 해당하는 각각의 분석 결과 외에도 두 요인 간에 영향을 주고 받는 연관성을 확인할 필요가 있음 - 주효과 검정뿐만 아니라 요인들이 연관되어 변수에 영향을 미치는 상호 작용 효과를 검정 - 상호작용 효과 : 두개의 요인이 동시에 작용하여 변수에 미치는 효과를 의미
- 일원분석 실습
import pandas as pd
df = pd.read_csv('이원분산분석_실습.csv', 'sep='.', encoding='CP949')
!pip install pingouin
!pip install scikit-posthocs
import scipy as sp
import numpy as np
import pingouin as pg
import scikit_posthocs
df1= df[['store', 'area', 'satisfaction']]
pd.options.display.float_format='{:3f}'.format
print(pg.anova(dv='satisfaction', between=['store', 'area'], data=df1))
- 데이터 프레임‘df’에서 store, area, satisfaction 세 열만 선택하여 새로운 df1을 생성- pd.options.display.float_format : 데이터 프레임에 부동 소수점 숫자를 표시할 때의 형식 지정 - ‘{:3f}’. : 소수점 이하 3자리까지 표시하도록 설정
pg.anova(dv=‘satisfaction’, between=[‘store’, ‘area’, data=df1]) - satisfaction’을 변수로, ‘store’와 ‘area’를 요인으로 하는 이원분산분석을 수행함 - 해당코드는 ‘df1’ 내에서 이러한 분석을 수행 - 결과는 ‘store’와 ‘area’의 다른수준 조합이 ‘satisfaction’에 미치는 영향을 평가함
- Scikit-posthocs 라이브러리의 posthoc_scheffe함수를 호출하여 Scheffé의사 후 검정을 수행함 - val_col='satisfaction'는 분석할 값(수치데이터)이 포함된 열이'satisfaction' - group_col='store'는 그룹을 나타내는 열이'store'임을 지정- > 위의 것을 store에서 area로 변경
다원분산분석(multi-way ANOVA) - 세 가지 이상의 기준이 되는 요인으로 비교하고자하는 변수의 평균 차이가 집단 간에 존재하는지를 조사하는 것
다변량분산분석(multi-variate ANOVA) - 1개이상이 되는 요인에 대해 비교하고자 하는 2개 이상의 변수를 기준으로 집단간에 차이가 있는 지를 조사하는 것
Correlation Analysis 상관 분석
두 변수(특징 변수와 목표 변수) 간의 연관성을 파악하기 위해 상관분석
상관분석은 상관관계의 정도를 나타내는 지수인 상관계수를 통해 분석
피어슨 상관계수(표본 상관계수) : 𝑋와 𝑌가 함께 변하는 정도를𝑋와𝑌가 각각 변하는 정도로 나눈 것
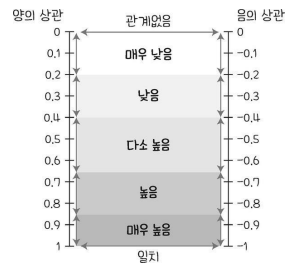
상관관계의 정도의 시각화
상관 분석을 통해 얻을 수 있는 정보 - 두 변수 간의 선형 관계를 파악 - 그 관계가 양의 관계인지 또는 음의 관계인지 파악 - 높은 상관 관계를 가지는 특징 변수들을 파악(다중 선형 회귀 모델에서 필요함)
상관 분석 실습 코드
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
x = [90, 64, 94, 57, 82, 92, 84, 72, 52, 86, 73, 82, 78, 68, 54, 92, 65, 76, 83, 95]
y = [86, 65, 89, 62, 74, 64, 98, 85, 62, 84, 84, 83, 59, 64, 55, 95, 70, 72, 88, 93]
plt.scatter(x, y, color='b', s=20) #‘x’와‘y’ 데이터를 파란색 점으로 산점도 그래프에 표시함, 점의 크기는 s=2-으로 지정함
plt.xlabel('x')
plt.ylabel('y')
plt.show()
print(np.corrcoef(x, y)) # ‘x’와와‘‘y’ 데이터집합 간의 상관계수 행렬을 계산함
print(sp.stats.pearsonr(x, y)) # scipy. stats 모듈의‘pearsonr’함수를 사용하여 ‘x’와 ‘y’의 피어슨 상관 계수를 계산함
상관관계 =/= 인과관계
Orange3
좌측 : 위젯을 제공함 - 각 위젯을 끌어들어서 화면(캔버스)에 배치하면 데이터 흐름을 시작적으로 구성할 수 있음
오른쪽으로 가로가 있는 것 : 입력만 가능, 왼쪽으로 있는 것 : 출력만 가능, 양쪽으로 있는 것 : 둘다 가능
이렇게 이어서 각각의 연결을 할 수 있다.
Machine Learning 머신러닝
인공지능 - 인간의 지능을 모방하여 사람이 하는 일을 컴퓨터(기계)가 할 수 있도록 하는 기술 - 인공지능을 구현하는 방법으로 머신러닝과 딥러닝이있음
머신러닝 - 주어진 데이터를 인간이 먼저 처리함 (전처리) - 이미지 데이터라면 사람이 학습(train) 데이터를 컴퓨터가 인식할 수 있도록 준비 해두어야 함 - 범용적인 목적을 위해 제작된 것으로 데이터의 특징을 스스로 추출하지 못함 : 인간이 해줘야함 -> 각 데이터(이미지)의 특성을 컴퓨터에 인식시키고 학습시켜 문제를 해결
지도학습 - 정답이 주어진 데이터를 이용하여 학습한 후에 테스트 데이터에 대한 미래결과를 예측하는 방법
Linear Regression 선형 회귀 시스템
- 트레이닝 데이터를 사용하여 데이터의 특성과 상관관계를 분석하고, 이를 기반으로 모델을 학습시켜, 트레이닝 데이터에 포함되지 않은 새로운 데이터에 대한 결과를 연속적인 숫자 값으로 예측하는 과정
학습 : 트레이닝 데이터의 분석을 통해 데이터의 분포를 가장 잘 표현하는 선형관계를 나타내는 일차함수의 가중치𝑾 와 바이어스𝒃를 찾아가는 과정 : 𝑦 = 𝑊𝑥 + 𝑏함수 식으로 트레이닝 데이터를 표현
오차 : 정답𝒕와 계산값𝒚의 차이 - 오차가 크다면 우리가 임의로 가정한𝑦 = 𝑊𝑥 + 𝑏 함수의 가중치𝑊와 바이어스𝑏값이 잘못된 것 - 오차가 작다면 우리가 임의로 가정한 가중치𝑊와 바이어스𝑏값이 최적화 -> 미래값 예측도 정확할 것이라고 예상할 수 있음
손실 함수(Loss function, 비용함수) - 손실함수에서 오차를 계산할 때는 다음과 같이 (𝒕 − 𝒚) 𝟐을 사용함 - 한 오차의 제곱을 이용한 손실함수를 평균제곱오차(MSE)라고 하며 아래와 같이 간단한 수식으로 나타낼 수 있음 - 손실함수는 아래의 식에서 가중치 𝑾와 바이어스 𝒃에만 영향을 받는다는 것을 알 수 있음
- 머신러닝에서는 손실함수의 값을 최소로 하는 것이 가장 중요함
경사하강법 - 손실함수의 최솟값을 찾기 위한 다양한 방법 - 가중치𝑊에 대한 손실함수의 그래프는 아래의 그림과 같이 포물선 형태로 그려짐, 가중치𝑊 = 1에서 손실 함수는 최솟값0
Binary Classification 이진분류 시스템
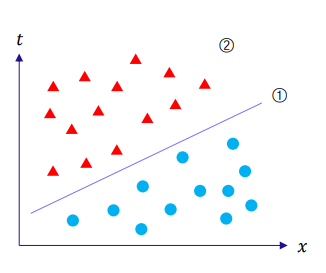
이진 분류 ① 주어진 트레이닝 데이터를 사용하여 ② 특징 변수와 목표 변수(두 가지 범주) 사이의 관계를 학습하고 ③ 이를 바탕으로 트레이닝 데이터에 포함되지 않은 새로운 데이터를 사전에 정의된 두 가지 범주 중 하나로 분류하는 예측 모델을 구축하는 과정
로지스틱 회귀 알고리즘
①트레이닝 데이터의 특성과 분포를 나타내는 최적의 직선을 찾고, ②해당 직선을 기준으로 데이터를 위(1)나 아래(0) 또는 왼쪽(1)이나 오른쪽(0) 등으로 분류하는 방법
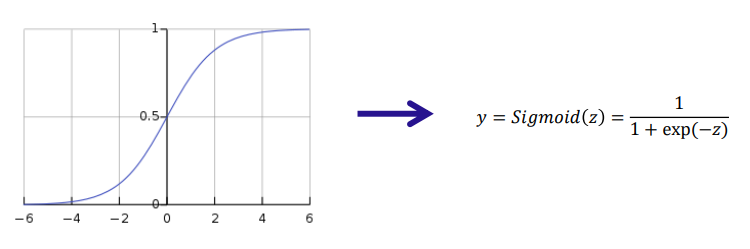
Sigmoid function - 시그모이드 함수의 함수식 표현은 아래와 같으며 0,1 범위의 값으로 변환함