TMDB에서 크롤링을 진행도 하여보았는데, 거의 동일한 것으로 확인이 되어서 캐글 데이터셋을 그대로 사용을 하기러 했습니다.
데이터 EDA 와 데이터 전처리
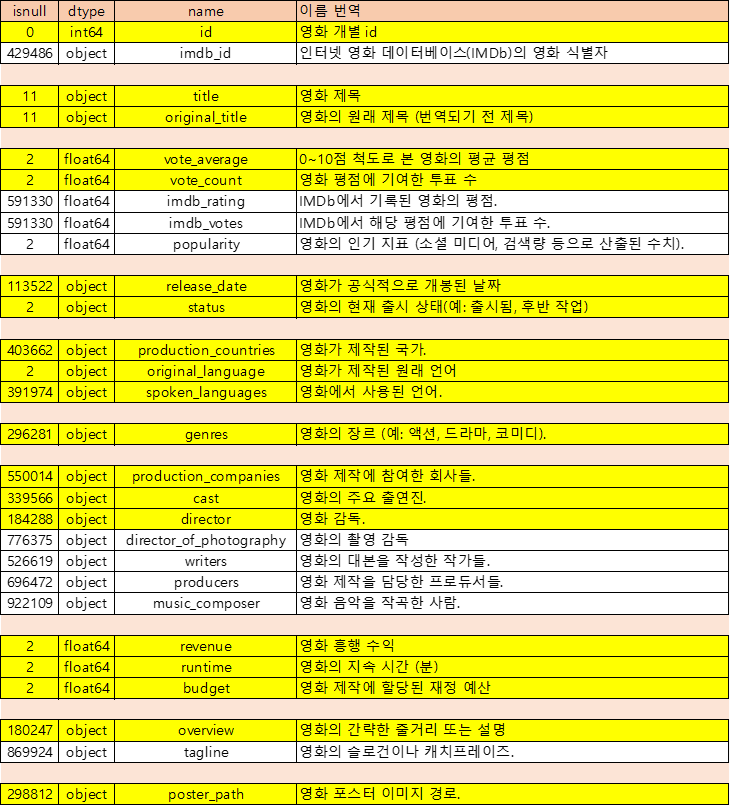
데이터 컬럼확인
데이터 컬럼을 확인해보면서 id의 경우 tmbd아이디의 결측치가 없으니 imdb의 아이디는 삭제후 tmdb 아이디만 사용했습니다.
그리고 영화제목은 필수이고, 영화의 평점과 기여한 투표수도 챙기기러 했습니다 .또한 투표수가 만약 없다면 imdb에서 가져오면 된다,라고 했지만 결측치가 적어서 그냥 삭제하기러 하고 사용을 하였습니다.
영하ㅗ의 상태는 개봉이 된 상태만 사용하기러 했고, 그 중에서도 개봉 날짜가 없는 경우에는 행을 삭제 하기러 했습니다.
또한 제작 국가, 언어는 사용을 할 만하고, 장르, 회사, cast, 감독, 수익, 시간, 예산 등도 사용하기러 했습니다.
overview의 경우에는 영화를 보여줄때 필요한 부분이므로 그대로 두었고, 포스터도 영화를 보여주기위해서 두기러 했습니다.
상관관계 분석
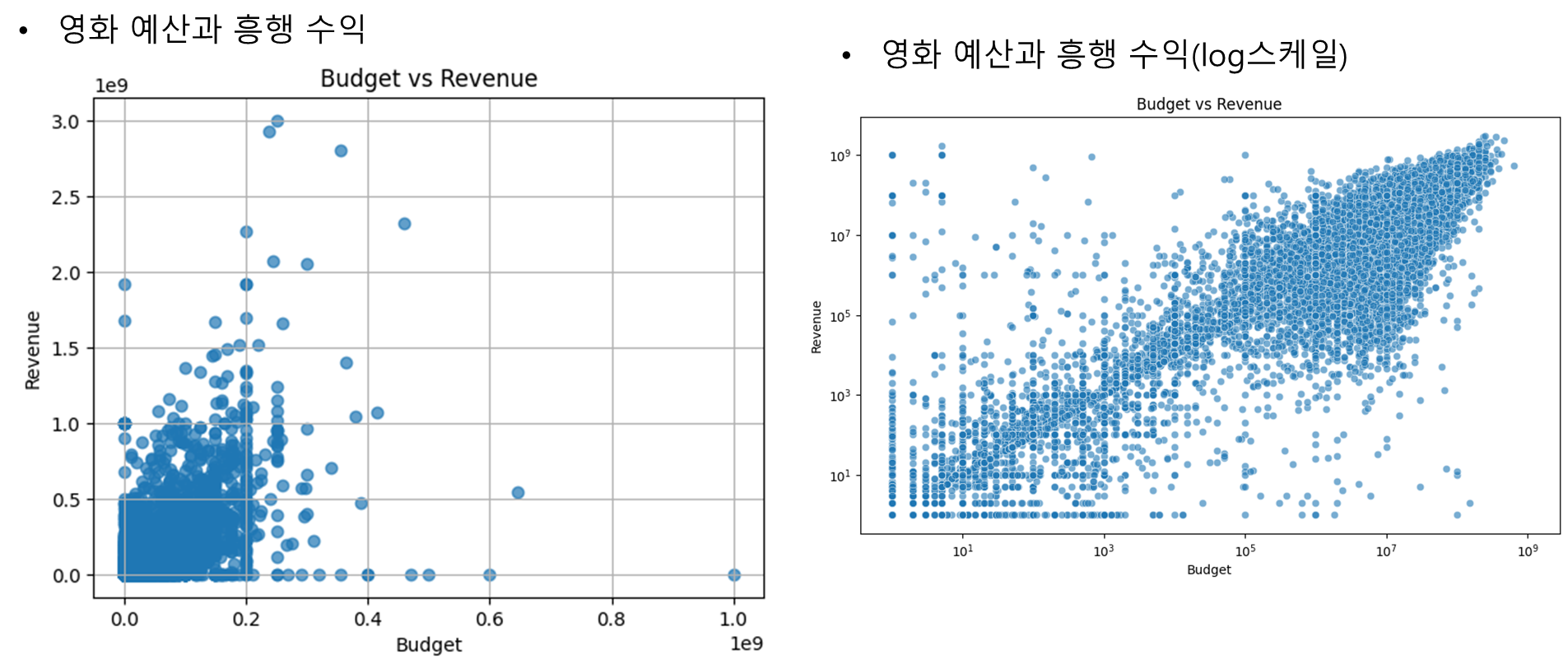
상관관계의 경우에는 서로 어떠한 관계가 있는지 확인을 하지 못했습니다. 오히려 투표각각이 상관관계가 낮은 것을 확인하고 하나만 선택을 하게 되었고, 상관관계가 높은 경우는 평점투표수와 흥행수익이었습니다. 이 둘을 확인하면 무언가 있을 것을 확인하였고, 그 외에도 제작예산과 흥행수익이 상관관계가 높다는 것을 확인했습니다.
여기서는 중요한 인사이트는 딱히 없었습니다.
각각 데이터 배치 확인
데이터 배치 확인을 해보았을 때, 모든 부분에 0으로 표기되는 값이 매우 많은 것을 확인했고, 이에 대한 문제를 해결해야겠다는 생각이 되었습니다.
영화 개봉 상태
개봉 상태는 개봉된 경우가 가장 많았고, 그 외의 경우엔 행을 삭제하기러 했습니다.
영화 언어
영화 언어는 영어가 압도적으로 많고, 그 뒤로 프랑스어, 스페인어, 독일어, 일본어, 중국어로 한국어는 10위였습니다.
한국인들에게 할 추천이므로 영어와 한국어만의 추천을 가지고 가기러 했습니다.
영화 예산과 흥행 수익
년도별 영화
장르별 영화
데이터 EDA를 진행하면서, 데이터 전처리를 어떻게 해야할지 방향성을 잡고, 그에 대해서 토의 한 결과, 결측치와 이상치 데이터는 삭제의 방향으로 잡았습니다.
이전에 경진대회에서 했던 것과는 다르게, 유명하고 잘 알려진 영화의 경우엔 데이터가 제대로 있을 것이고, 영화 추천에 있어서 사람들이 많이 본, 그런 영화들을 추천하고자 한다면, 영화 추천에 있어서 이게 올바른 선택인 것 같았습니다.
데이터 분석 및 처리 / Streamlit으로 UI 구현
팀에서 진행한 Streamlit말고 혼자서 제작을 조금 더 해보았습니다.
혼자 진행한 것은 배포를 하지 못하고, 그저 확인용으로 사용이 되었고 코드의 수정이 많이 필요한 상태입니다.
폴더구조
Streamlit에 대한 폴더 구조는 다음과 같이 구성을 해두었습니다.
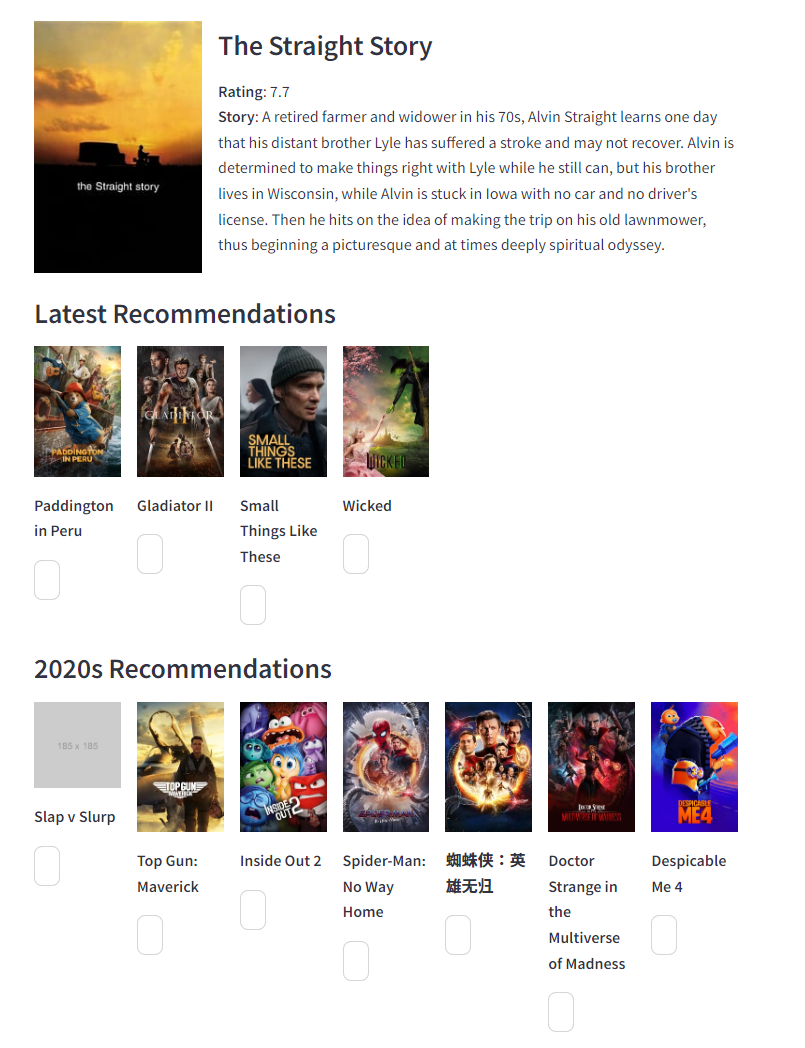
첫 홈페이지에서는 간단하게, 이렇게 어떤 추천을 통할 것인지에 대해서 뜨게 만들어두었어요.
메타데이터 기반 추천 시스템
추천보기 - 다양한 영화를 모아두었습니다. - 다양한 카테고리에 따라서 구성이 되게 했고, 아래에 버튼을 누르면 위에 내용이 뜨게 만들어두었습니다.
(오늘의 발견)전체 영화에서 랜덤으로 영화 추천 - 필터링 : 투표수가500이상, 폄점이 7점 이상, 1990년대 이후 개봉작 (오늘의 한국영화) 한국 영화에서 랜덤으로 영화 추천 - 필터링 :투표수가10이상, 폄점이 6점 이상, 1990년대 이후 개봉작 (인기 영어 영화) 제작언어가 영어인영화중에서추천 - 필터링 : 투표수가10이상, 제작언어가 en -스크리닝방법:투표수>평점>수익>최신 날짜 (100개를 모아, 7개씩 랜덤으로 보여줌) (인기 한국 영화) 제작언어가 한국어인영화중에서추천 - 필터링 : 투표수가10이상, 제작언어가 ko -스크리닝방법:투표수>평점>수익>최신 날짜 (100개를 모아, 7개씩 랜덤으로 보여줌) (10년전 영화) 개봉일이2014년 11월인 영화 - 필터링 :평점이 있음, 투표수가 10 이상 -스크리닝방법:수익>투표수>평점>최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
(러닝타임) 러닝타임이50분 이상, 60분 이하의 영화 - 필터링 :투표수가 100이상. 평점이 8이상 -스크리닝방법:수익>투표수>평점>최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌) (러닝타임) 러닝타임이 상위3%안에 드는 영화(149~201분) - 필터링 :투표수가 10이상 -스크리닝방법:수익>투표수>평점>최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌) (평점이 높은 영화) - 필터링 :예산과 수익이 0이 아닌 경우, 투표수가 100이상 -스크리닝방법:평점>투표수>최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌 (수익/예산 이 큰 영화) - 필터링 :투표수가 10이상, 2000년대 이후 개봉 -스크리닝방법:수익>투표수>평점>최신 날짜 (30개를 모아, 7개씩 랜덤으로 보여줌)
카테고리별 장르별 (Action, Adventure, Animation, Comedy, Crime,Documentary,Drama Family,Fantasy, History,Horror,Music,Mystery, Romance,Science Fiction, TV Movie,Thriller,War,Western) - 여러 개의 장르가 하나의 영화에 포함이 되는 경우가 많음-> 리스트화 시켜서 분석에 사용 -스크리닝방법:수익>투표수>평점>최신 날짜 (각 100개씩 추천 후, UI에서는 7개를 랜덤으로 보여줌 - 장르에 따라서 구성이 되게 했고, 아래에 버튼을 누르면 위에 내용이 뜨게 만들어두었습니다.
시리즈별 영화 (20th Century Fox,Columbia Pictures,Metro-Goldwyn-Mayer,New Line Cinema,Orion Pictures,Paramount Pictures,Touchstone Pictures,Universal Pictures,Walt Disney,Warner Bros. Pictures) - 회사에 따라서 구성이 되게 했고, 아래에 버튼을 누르면 위에 내용이 뜨게 만들어두었습니다.
- 회사 스크리닝 방법 : 수익이 높은 회사10개, 영화 개수가15개 초과인 회사만 - 필터링 : 투표수가10이상, 수익이 0이 아닌 경우 -스크리닝방법:수익>투표수>평점>최신 날짜 (각 회사별 15개를 모아, 7개씩 랜덤으로 보여줌)